Py: Decision Tree Classification#
This notebook was originally created by Hugh Miller for the Data Analytics Applications subject, as Exercise 5.10 - Spam detection with a decision tree in the DAA M05 Classification and neural networks module.
Data Analytics Applications is a Fellowship Applications (Module 3) subject with the Actuaries Institute that aims to teach students how to apply a range of data analytics skills, such as neural networks, natural language processing, unsupervised learning and optimisation techniques, together with their professional judgement, to solve a variety of complex and challenging business problems. The business problems used as examples in this subject are drawn from a wide range of industries.
Find out more about the course here.
Purpose:#
This notebook fits a decision tree on a spam dataset to identify spam emails based on features about the email.
References:#
The spam dataset is sourced from the University of California, Irvine Machine Learning Repository: Hopkins, M., Reeber, E., Forman, G., and Suermondt, J. (1999). Spambase Data Set [Dataset]. https://archive.ics.uci.edu/ml/datasets/Spambase.
This dataset contains the following:
4,601 observations, each representing an email originally collected from a Hewlett-Packard email server, of which 1,813 (39%) were identified as spam;
57 continuous features:
48 features of type ‘word_freq_WORD’ that represent the percentage (0 to 100) of words in the email that match ‘WORD’;
6 features of type ‘char_freq_CHAR’ that represent the percentage (0 to 100) of characters in the email that match ‘CHAR’;
1 feature, ‘capital_run_length_average’, that is the average length of uninterrupted sequences of capital letters in the email;
1 feature, ‘capital_run_length_longest’, that is the length of the longest uninterrupted sequence of capital letters in the email; and
1 feature, ‘capital_run_length_total’, that is the total number of capital letters in the email; and
a binary response variable that takes on a value 0 if the email is not spam and 1 if the email is spam.
Packages#
This section imports the packages that will be required for this exercise/case study.
import pandas as pd
import matplotlib.pyplot as plt
# Used to build the decision tree and evaluate it
from sklearn import tree
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score
import sklearn.metrics as metrics
# Used to graph the decision tree
import graphviz
from sklearn.tree import export_graphviz
from IPython.display import Image
Data#
This section:
imports the data that will be used in the modelling; and
explores the data.
Import data#
# Create a list of headings for the data.
namearray = [
'word_freq_make',
'word_freq_address',
'word_freq_all',
'word_freq_3d',
'word_freq_our',
'word_freq_over',
'word_freq_remove',
'word_freq_internet',
'word_freq_order',
'word_freq_mail',
'word_freq_receive',
'word_freq_will',
'word_freq_people',
'word_freq_report',
'word_freq_addresses',
'word_freq_free',
'word_freq_business',
'word_freq_email',
'word_freq_you',
'word_freq_credit',
'word_freq_your',
'word_freq_font',
'word_freq_000',
'word_freq_money',
'word_freq_hp',
'word_freq_hpl',
'word_freq_george',
'word_freq_650',
'word_freq_lab',
'word_freq_labs',
'word_freq_telnet',
'word_freq_857',
'word_freq_data',
'word_freq_415',
'word_freq_85',
'word_freq_technology',
'word_freq_1999',
'word_freq_parts',
'word_freq_pm',
'word_freq_direct',
'word_freq_cs',
'word_freq_meeting',
'word_freq_original',
'word_freq_project',
'word_freq_re',
'word_freq_edu',
'word_freq_table',
'word_freq_conference',
'char_freq_;',
'char_freq_(',
'char_freq_[',
'char_freq_!',
'char_freq_$',
'char_freq_#',
'capital_run_length_average',
'capital_run_length_longest',
'capital_run_length_total',
'Spam_fl' ]
# Read in the data from the Stanford website.
spam = pd.read_csv("http://www.web.stanford.edu/~hastie/ElemStatLearn/datasets/spam.data", delim_whitespace=True,
header=None,
names=namearray
)
Explore data (EDA)#
# Check the dimensions of the data.
print(spam.info())
# Print the first 10 observations from the data.
print(spam.head(10))
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 4601 entries, 0 to 4600
Data columns (total 58 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 word_freq_make 4601 non-null float64
1 word_freq_address 4601 non-null float64
2 word_freq_all 4601 non-null float64
3 word_freq_3d 4601 non-null float64
4 word_freq_our 4601 non-null float64
5 word_freq_over 4601 non-null float64
6 word_freq_remove 4601 non-null float64
7 word_freq_internet 4601 non-null float64
8 word_freq_order 4601 non-null float64
9 word_freq_mail 4601 non-null float64
10 word_freq_receive 4601 non-null float64
11 word_freq_will 4601 non-null float64
12 word_freq_people 4601 non-null float64
13 word_freq_report 4601 non-null float64
14 word_freq_addresses 4601 non-null float64
15 word_freq_free 4601 non-null float64
16 word_freq_business 4601 non-null float64
17 word_freq_email 4601 non-null float64
18 word_freq_you 4601 non-null float64
19 word_freq_credit 4601 non-null float64
20 word_freq_your 4601 non-null float64
21 word_freq_font 4601 non-null float64
22 word_freq_000 4601 non-null float64
23 word_freq_money 4601 non-null float64
24 word_freq_hp 4601 non-null float64
25 word_freq_hpl 4601 non-null float64
26 word_freq_george 4601 non-null float64
27 word_freq_650 4601 non-null float64
28 word_freq_lab 4601 non-null float64
29 word_freq_labs 4601 non-null float64
30 word_freq_telnet 4601 non-null float64
31 word_freq_857 4601 non-null float64
32 word_freq_data 4601 non-null float64
33 word_freq_415 4601 non-null float64
34 word_freq_85 4601 non-null float64
35 word_freq_technology 4601 non-null float64
36 word_freq_1999 4601 non-null float64
37 word_freq_parts 4601 non-null float64
38 word_freq_pm 4601 non-null float64
39 word_freq_direct 4601 non-null float64
40 word_freq_cs 4601 non-null float64
41 word_freq_meeting 4601 non-null float64
42 word_freq_original 4601 non-null float64
43 word_freq_project 4601 non-null float64
44 word_freq_re 4601 non-null float64
45 word_freq_edu 4601 non-null float64
46 word_freq_table 4601 non-null float64
47 word_freq_conference 4601 non-null float64
48 char_freq_; 4601 non-null float64
49 char_freq_( 4601 non-null float64
50 char_freq_[ 4601 non-null float64
51 char_freq_! 4601 non-null float64
52 char_freq_$ 4601 non-null float64
53 char_freq_# 4601 non-null float64
54 capital_run_length_average 4601 non-null float64
55 capital_run_length_longest 4601 non-null int64
56 capital_run_length_total 4601 non-null int64
57 Spam_fl 4601 non-null int64
dtypes: float64(55), int64(3)
memory usage: 2.0 MB
None
word_freq_make word_freq_address word_freq_all word_freq_3d \
0 0.00 0.64 0.64 0.0
1 0.21 0.28 0.50 0.0
2 0.06 0.00 0.71 0.0
3 0.00 0.00 0.00 0.0
4 0.00 0.00 0.00 0.0
5 0.00 0.00 0.00 0.0
6 0.00 0.00 0.00 0.0
7 0.00 0.00 0.00 0.0
8 0.15 0.00 0.46 0.0
9 0.06 0.12 0.77 0.0
word_freq_our word_freq_over word_freq_remove word_freq_internet \
0 0.32 0.00 0.00 0.00
1 0.14 0.28 0.21 0.07
2 1.23 0.19 0.19 0.12
3 0.63 0.00 0.31 0.63
4 0.63 0.00 0.31 0.63
5 1.85 0.00 0.00 1.85
6 1.92 0.00 0.00 0.00
7 1.88 0.00 0.00 1.88
8 0.61 0.00 0.30 0.00
9 0.19 0.32 0.38 0.00
word_freq_order word_freq_mail ... char_freq_; char_freq_( \
0 0.00 0.00 ... 0.00 0.000
1 0.00 0.94 ... 0.00 0.132
2 0.64 0.25 ... 0.01 0.143
3 0.31 0.63 ... 0.00 0.137
4 0.31 0.63 ... 0.00 0.135
5 0.00 0.00 ... 0.00 0.223
6 0.00 0.64 ... 0.00 0.054
7 0.00 0.00 ... 0.00 0.206
8 0.92 0.76 ... 0.00 0.271
9 0.06 0.00 ... 0.04 0.030
char_freq_[ char_freq_! char_freq_$ char_freq_# \
0 0.0 0.778 0.000 0.000
1 0.0 0.372 0.180 0.048
2 0.0 0.276 0.184 0.010
3 0.0 0.137 0.000 0.000
4 0.0 0.135 0.000 0.000
5 0.0 0.000 0.000 0.000
6 0.0 0.164 0.054 0.000
7 0.0 0.000 0.000 0.000
8 0.0 0.181 0.203 0.022
9 0.0 0.244 0.081 0.000
capital_run_length_average capital_run_length_longest \
0 3.756 61
1 5.114 101
2 9.821 485
3 3.537 40
4 3.537 40
5 3.000 15
6 1.671 4
7 2.450 11
8 9.744 445
9 1.729 43
capital_run_length_total Spam_fl
0 278 1
1 1028 1
2 2259 1
3 191 1
4 191 1
5 54 1
6 112 1
7 49 1
8 1257 1
9 749 1
[10 rows x 58 columns]
Modelling#
This section:
fits a model; and
evaluates the fitted model.
Fit model#
# Build a decision tree to classify an email as spam or non-spam.
X = spam.iloc[:,:-1] # Drops the last column of the dataframe that contains the spam indicator (response).
Y = spam['Spam_fl'].values
X_train,X_test,Y_train,Y_test = train_test_split(X,Y,test_size = 0.25, random_state=42)
# This separates the data into training (75%) and test (25%) datasets.
alpha = 0.001 # Experiment with changing this value of alpha.
# What happens to the size of the decision tree and its accuracy?
criteria = 'gini' # Experiment with changing this to an 'entropy' criterion
# What happens to the size of the decision tree and its accuracy?
classifier = tree.DecisionTreeClassifier(random_state=0, ccp_alpha=alpha, min_samples_split=20, criterion=criteria, min_samples_leaf=5)
classifier.fit(X_train, Y_train)
tree.plot_tree(classifier)
Y_predict = classifier.predict(X_test)

Evaluate model#
# Calculate the confusion matrix and test accuracy.
print('Test confusion matrix:')
print(confusion_matrix(Y_test, Y_predict))
print('Test accuracy is {:.4f}.'.format(accuracy_score(Y_test, Y_predict)))
# Calculate the AUC and ROC.
Y_prob = classifier.predict_proba(X_test)
fpr, tpr, threshold = metrics.roc_curve(Y_test, Y_prob[:,1:2])
roc_auc = metrics.auc(fpr, tpr)
print('AUC is {:.4f}.'.format(roc_auc))
# Calculate the number of terminal nodes in the tree.
num_nodes = (1+classifier.tree_.node_count)/2
print('The number of terminal nodes is {:.0f}.'.format(num_nodes))
Test confusion matrix:
[[636 40]
[ 61 414]]
Test accuracy is 0.9123.
AUC is 0.9572.
The number of terminal nodes is 37.
# Print the tree in a format that is easier to visualise.
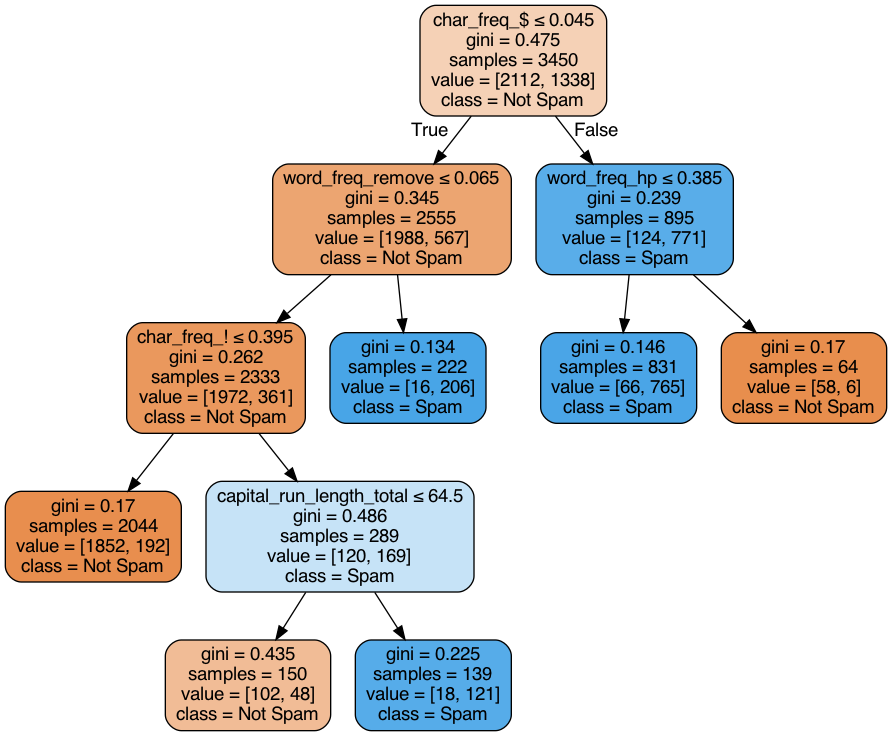
clf2 = tree.DecisionTreeClassifier(random_state=0, ccp_alpha=0.01, min_samples_split=20, criterion="gini",min_samples_leaf=5)
clf2.fit(X_train, Y_train)
export_graphviz(clf2, 'DAA_M05_Fig11.dot', feature_names = X_train.columns,class_names=['Not Spam', 'Spam'],filled=True, rounded=True,special_characters=True)
! dot -Tpng DAA_M05_Fig11.dot -o DAA_M05_Fig11.png
Image(filename='DAA_M05_Fig11.png')