Py: Investigating Neural Network Biases with ChatGPT#
But not in the way you think…
An Analytics Snippet By Jacky Poon.
In this notebook we will use the assistance of ChatGPT to use neural network models with early stopping to predict claims data and see if it is biased.
Here, bias is referring to the model making predictions that are systematically higher or lower. This is important because in many practical actuarial applications, whilst it is helpful to be able to predict which are the high risk segments and which are the low risk segments, having the whole portfolio systematically underpriced or overpriced will lead to unfortunate outcomes.
We will see if we can replicate similar findings to Wuthrich 2019. In the paper Wuthrich describes how use of the early stopping technique to limit over-fitting introduced biases into estimates of the mean, and considers the use of regularisation techniques to prevent this.
Early stopping is a common method in machine learning to prevent overfitting. You select a validation dataset and then during the model training process, if we observe at some point that further training is not improving performance, we stop.
Our investigation follows my earlier notebook. In the article we described how to make incremental changes to a chain ladder to progress to a probabilistic neural network. We also shared several techniques that help the model training process, with faster convergence and better stability. In that notebook, early stopping was not used, so estimates aligned well to the mean within the training data. Instead, regularisation was used to try to prevent overfitting. However, regularisation requires hyperparameter searches to find the value that finds the right balance between under- and over-fitting, whereas early stopping would seem to automatically find the right balance.
So it would be interesting to test to see if the Wuthrich findings of biases apply to our approach as well.
ChatGPT prompt:#
We used the following prompt to start our code.
Write a python script that fits a feedforward neural network with one hidden layer on a
pandastabular dataset. Usepytorch, with early stopping. The response column isclaims. There is an exposure weight columnexpo. Numerical features areage,ac,power,densCategorical features aregas,brand,area, andct. Explain the code.
This was run on ChatGPT’s free version in mid May 2023. You may get different output as the large language model does not appear to be deterministic - different runs will produce different code, sometimes a different style, and often different bugs or functionality.
We will include ChatGPT’s code descriptions, which were originally at the end, in-line with the code in italics to make it easier to follow, and annotate any adjustments we made.
Response:#
Certainly! Below is a Python script that fits a feedforward neural network with embeddings on categorical features and one hidden layer using PyTorch on a Pandas tabular dataset:
Import the necessary libraries, including torch for deep learning operations, numpy for numerical computations, and pandas for data manipulation.
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder, MinMaxScaler # We added MinMaxScaler for later
from sklearn.metrics import mean_squared_error
from matplotlib import pyplot as plt # Added this for extra diagnostics.
num_models = 50
Define a class called FeedForwardNet, which represents the feedforward neural network model. It inherits from the nn.Module class, the base class for all neural network modules in PyTorch.
Inside the FeedForwardNet class, define the neural network architecture in the init method. It consists of an embedding layer for each categorical feature, followed by a hidden layer and an output layer.
Implement the forward pass of the neural network in the forward method. The forward pass involves embedding the categorical features, concatenating them with the numerical features, and passing the concatenated tensor through the hidden and output layers.
The prompt does a good job and produces what is asked for. There is an undocumented dropout layer with 20% dropout which was not part of the ask, which we will take out to simplify the logic.
In Wuthrich’s paper, a multi-layer network is used with (20, 15, 10) hidden neurons, in our prompt we have only asked for a single hidden layer. We can change this to take a list of hidden sizes by asking:
Modify this code to take in a list of hidden layer sizes for a multi-layer model: and including the code for the
FeedForwardNetclass.
We also make some amendments based on our earlier work.
In our prompt, we neglected to mention we wanted to add an exponential transform at the end to have non-negative estimates analogous to a log-link GLM, so we amend the code to add torch.exp at end.
Additionally, we initialise as follows to improve model training:
Final layer weights to zero
Final layer bias to an additional parameter
init_bias.
# Define the neural network class
class FeedForwardNet(nn.Module):
def __init__(self, num_numerical_feats, num_categorical_feats, embedding_sizes, hidden_sizes, init_bias): # was hidden_size originally
super(FeedForwardNet, self).__init__()
self.embeddings = nn.ModuleList([
nn.Embedding(num_classes, emb_size) for num_classes, emb_size in embedding_sizes
])
self.num_numerical_feats = num_numerical_feats
self.num_categorical_feats = num_categorical_feats
self.total_embed_size = sum([emb_size for _, emb_size in embedding_sizes])
self.input_size = self.num_numerical_feats + self.total_embed_size
# self.fc1 = nn.Linear(self.input_size, hidden_size)
self.hidden_layers = nn.ModuleList([
nn.Linear(self.input_size if i == 0 else hidden_sizes[i - 1], hidden_size)
for i, hidden_size in enumerate(hidden_sizes)
])
# self.fc2 = nn.Linear(hidden_size, 1)
self.fc2 = nn.Linear(hidden_sizes[-1], 1)
nn.init.zeros_(self.fc2.weight) # Initialise to zero
self.fc2.bias.data = torch.tensor(init_bias)
# self.dropout = nn.Dropout(p=0.2)
def forward(self, x_numerical, x_categorical):
embedded_x = [embedding(x_categorical[:, i]) for i, embedding in enumerate(self.embeddings)]
embedded_x = torch.cat(embedded_x, dim=1)
x = torch.cat([embedded_x, x_numerical], dim=1)
# x = self.dropout(x)
# x = torch.relu(self.fc1(x))
for hidden_layer in self.hidden_layers:
x = torch.relu(hidden_layer(x))
# x = self.dropout(x)
x = self.fc2(x)
return torch.exp(x) #Exp output
Load the dataset using pd.read_csv() and split it into training and validation sets using train_test_split() from scikit-learn.
We did not give the dataset a file, so it was naming it by a placeholder 'your_dataset.csv'. We are using the data from Wu ̈thrich–Buser, the link is here.
# Load the dataset
data = pd.read_csv("MTPL_data.csv", sep=";").set_index("id")
# Split the dataset into training and validation sets
train_data, val_data = train_test_split(data, test_size=0.2, random_state=42)
The dataset looks like this by the way:
data
| claims | expo | age | ac | power | gas | brand | area | dens | ct | truefreq | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| id | |||||||||||
| 1 | 0 | 0.33 | 66 | 4 | 3 | Regular | B12 | B | 83 | BE | 0.059941 |
| 2 | 0 | 0.08 | 31 | 1 | 7 | Diesel | B1 | A | 34 | BL | 0.119216 |
| 3 | 0 | 0.92 | 60 | 6 | 5 | Diesel | B1 | C | 223 | AG | 0.074344 |
| 4 | 0 | 1.00 | 66 | 4 | 2 | Diesel | B1 | C | 283 | FR | 0.092829 |
| 5 | 0 | 0.63 | 63 | 3 | 5 | Regular | B12 | B | 74 | VS | 0.049981 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 499996 | 0 | 0.15 | 32 | 3 | 2 | Diesel | B1 | C | 204 | FR | 0.100843 |
| 499997 | 0 | 0.86 | 40 | 2 | 2 | Regular | B12 | D | 617 | FR | 0.167433 |
| 499998 | 0 | 0.74 | 46 | 7 | 4 | Regular | B1 | C | 238 | VD | 0.084457 |
| 499999 | 0 | 1.00 | 72 | 5 | 3 | Diesel | B2 | B | 94 | VS | 0.070113 |
| 500000 | 0 | 0.64 | 31 | 1 | 1 | Diesel | B12 | C | 323 | BL | 0.165031 |
500000 rows × 11 columns
Define the categorical features and numerical features based on the dataset columns.
Encode the categorical features using LabelEncoder() from scikit-learn. This is necessary to convert the categorical features into numerical representations suitable for training the neural network.
ChatGPT lists the features as instructed, but we discover after the fact that Wuthrich has area as continuous, so we’ll adjust the code accordingly.
We’ll create the label encoders based on the full dataset instead of the training dataset only, to avoid errors from missing levels.
# Define the categorical features and numerical features
categorical_feats = ['gas', 'brand', 'area', 'ct']
numerical_feats = ['age', 'ac', 'power', 'dens']
# Encode the categorical features using LabelEncoder
label_encoders = {}
for feat in categorical_feats:
label_encoders[feat] = LabelEncoder()
label_encoders[feat].fit(data[feat])
train_data[feat] = label_encoders[feat].transform(train_data[feat])
val_data[feat] = label_encoders[feat].transform(val_data[feat])
ChatGPT only label encodes the categorical variables, but we should standardise our numerical inputs:
# Standardize the categorical features using LabelEncoder
scaler = {}
for feat in numerical_feats:
scaler[feat] = MinMaxScaler()
train_data[feat] = scaler[feat].fit_transform(train_data[feat].values.reshape(-1, 1))
val_data[feat] = scaler[feat].transform(val_data[feat].values.reshape(-1, 1))
Define the embedding sizes for each categorical feature. These sizes determine the dimensions of the embedding vectors for each categorical feature. Usually, the embedding size is chosen to be smaller than the number of unique values in the feature but larger than half of it.
# Define the embedding sizes for categorical features
embedding_sizes = [(len(train_data[feat].unique()), min(50, (len(train_data[feat].unique()) + 1) // 2)) for feat in categorical_feats]
Convert the dataset columns into PyTorch tensors, which are required for training the neural network model.
We neglected to mention this in the prompt, but we actually want to divide claims by exposure here to get y.
# Convert the dataset to PyTorch tensors
x_train_numerical = torch.tensor(train_data[numerical_feats].values, dtype=torch.float32)
x_train_categorical = torch.tensor(train_data[categorical_feats].values, dtype=torch.long)
# y_train = torch.tensor(train_data['claims'].values, dtype=torch.float32)
y_train = torch.tensor(train_data['claims'].values / train_data['expo'].values, dtype=torch.float32)
exposure_train = torch.tensor(train_data['expo'].values, dtype=torch.float32)
x_val_numerical = torch.tensor(val_data[numerical_feats].values, dtype=torch.float32)
x_val_categorical = torch.tensor(val_data[categorical_feats].values, dtype=torch.long)
# y_val = torch.tensor(val_data['claims'].values, dtype=torch.float32)
y_val = torch.tensor(val_data['claims'].values / val_data['expo'].values, dtype=torch.float32)
exposure_val = torch.tensor(val_data['expo'].values, dtype=torch.float32)
We did not mention it in the prompt, but let’s calculate our mean so that we can see that it is aligning to that value.
avg_claim = train_data['claims'].values.sum() / train_data['expo'].values.sum()
avg_claim
0.10265948983820225
(y_train * exposure_train).sum() / train_data['expo'].values.sum()
tensor(0.1027)
Define the hyperparameters such as the hidden layer size, learning rate, batch size, number of epochs, and early stopping epochs.
The batch_size is generated, but it does not look like it is actually used in the later generated code. We prefer using the whole dataset, so this is fine.
We make a few adjustments to hyperparams.
# Define the hyperparameters
# hidden_size = 64
hidden_size = [20, 15, 10] # Replace with the multi-layer parameters.
# learning_rate = 0.001
# batch_size = 32
# num_epochs = 100
# early_stopping_epochs = 10
# Overwrite those hyperparameters with these
learning_rate = 0.01
num_epochs = 9999 # should not be a factor, we train until early stopping kicks in
early_stopping_epochs = 10
Create an instance of the FeedForwardNet model.
We pass on the init_bias parameter here.
# Create an instance of the FeedForwardNet model
model = FeedForwardNet(len(numerical_feats), len(categorical_feats), embedding_sizes, hidden_size, init_bias = np.log(avg_claim).astype(np.float32))
# Test that the init_bias works, what is the initial mean?
y_pred = model(x_train_numerical, x_train_categorical)
(y_pred.squeeze() * exposure_train).sum() / exposure_train.sum()
tensor(0.1027, grad_fn=<DivBackward0>)
Define the loss function (mean squared error) and the optimizer (Adam optimizer) to train the model.
We would like to do the exposure weights a little differently. We will have reduction=’none’ and keep the loss output as individual loss values per row instead of the sum. This allows us to multiply the loss per record by the exposure weight per record later.
We’ll also swap to Poisson Loss.
# Define the loss function
# criterion = nn.MSELoss(reduction='sum')
criterion = nn.PoissonNLLLoss(reduction='none', log_input=False)
# Define the optimizer
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
Train the model for the specified number of epochs. In each epoch, perform forward and backward passes, update the model’s parameters, and calculate the validation loss. If the validation loss is the lowest so far, save the model’s state.
We add some debug output for diagnostics.
# Train the model
best_val_loss = np.inf
best_epoch = 0
for epoch in range(num_epochs):
model.train()
optimizer.zero_grad()
y_pred = model(x_train_numerical, x_train_categorical)
# loss = criterion(y_pred.squeeze() * exposure_train, y_train * exposure_train)
loss = (criterion(y_pred.squeeze(), y_train) * exposure_train).sum() / exposure_train.sum()
loss.backward()
optimizer.step()
model.eval()
with torch.no_grad():
y_val_pred = model(x_val_numerical, x_val_categorical)
# val_loss = criterion(y_val_pred.squeeze() * exposure_val, y_val * exposure_val)
val_loss = (criterion(y_val_pred.squeeze(), y_val) * exposure_val).sum() / exposure_val.sum()
if val_loss < best_val_loss:
best_val_loss = val_loss
best_epoch = epoch
torch.save(model.state_dict(), 'best_model.pt')
# Added for diagnostics
if (val_loss < best_val_loss) | (epoch % 10 == 0):
print(
"Epoch:", epoch,
"Train_Diff:", ((y_pred.squeeze() * exposure_train - y_train * exposure_train).sum() / exposure_train.sum()).item(),
"Train_Mean:", ((y_pred.squeeze() * exposure_train).sum() / exposure_train.sum()).item(),
"Train_Loss", loss.item(),
"Val_mean", ((y_val_pred.squeeze() * exposure_val).sum() / exposure_val.sum()).item(),
"Val_loss", val_loss.item(),
)
if epoch - best_epoch >= early_stopping_epochs:
print("Stopping at:", best_epoch)
break
Epoch: 0 Train_Diff: 3.9570383081333205e-10 Train_Mean: 0.10265947878360748 Train_Loss 0.33634716272354126 Val_mean 0.10276821255683899 Val_loss 0.336696594953537
Epoch: 10 Train_Diff: 0.0005192473763599992 Train_Mean: 0.10317873954772949 Train_Loss 0.3340966999530792 Val_mean 0.10280803591012955 Val_loss 0.3345138132572174
Epoch: 20 Train_Diff: 0.000555766629986465 Train_Mean: 0.10321525484323502 Train_Loss 0.3329228162765503 Val_mean 0.10316438227891922 Val_loss 0.3333604633808136
Epoch: 30 Train_Diff: 0.00022463459754362702 Train_Mean: 0.10288412868976593 Train_Loss 0.33167240023612976 Val_mean 0.10189294815063477 Val_loss 0.33199846744537354
Epoch: 40 Train_Diff: 0.00515005411580205 Train_Mean: 0.10780954360961914 Train_Loss 0.33076417446136475 Val_mean 0.09964833408594131 Val_loss 0.33111655712127686
Epoch: 50 Train_Diff: -0.0002511663769837469 Train_Mean: 0.10240831226110458 Train_Loss 0.3297358453273773 Val_mean 0.10654579848051071 Val_loss 0.33056363463401794
Epoch: 60 Train_Diff: 0.002754278015345335 Train_Mean: 0.1054137572646141 Train_Loss 0.32892730832099915 Val_mean 0.09867089241743088 Val_loss 0.32982489466667175
Epoch: 70 Train_Diff: 3.5053705005339e-07 Train_Mean: 0.10265983641147614 Train_Loss 0.32785457372665405 Val_mean 0.09791050851345062 Val_loss 0.32911568880081177
Epoch: 80 Train_Diff: 0.005469439085572958 Train_Mean: 0.10812892764806747 Train_Loss 0.32726752758026123 Val_mean 0.09609229862689972 Val_loss 0.3288998305797577
Epoch: 90 Train_Diff: 0.0024685768876224756 Train_Mean: 0.10512805730104446 Train_Loss 0.3264632225036621 Val_mean 0.09715571999549866 Val_loss 0.3284188508987427
Epoch: 100 Train_Diff: -0.002204097807407379 Train_Mean: 0.1004553884267807 Train_Loss 0.3260534703731537 Val_mean 0.10135945677757263 Val_loss 0.32796788215637207
Epoch: 110 Train_Diff: -0.004026252310723066 Train_Mean: 0.09863324463367462 Train_Loss 0.32590925693511963 Val_mean 0.10565565526485443 Val_loss 0.3279320001602173
Epoch: 120 Train_Diff: 0.003851202316582203 Train_Mean: 0.1065106987953186 Train_Loss 0.3255639374256134 Val_mean 0.0999462902545929 Val_loss 0.32771018147468567
Epoch: 130 Train_Diff: -0.0011717552551999688 Train_Mean: 0.10148773342370987 Train_Loss 0.32516470551490784 Val_mean 0.10182797163724899 Val_loss 0.3276842534542084
Stopping at: 121
Load the best model’s state from the saved file.
# Load the best model
model.load_state_dict(torch.load('best_model.pt'))
<All keys matched successfully>
Prepare the test set data and make predictions on it using the best model.
ChatGPT does not actually prepare the test set data, so we need to code this up ourselves. For this test we’ll just use our original full dataset.
test_data = data.copy()
for feat in categorical_feats:
test_data[feat] = label_encoders[feat].transform(test_data[feat])
for feat in numerical_feats:
test_data[feat] = scaler[feat].transform(test_data[feat].values.reshape(-1, 1))
Calculate the test loss (mean squared error) and the root mean squared error (RMSE) for the test set.
Print the test RMSE.
# Make predictions on the test set
x_test_numerical = torch.tensor(test_data[numerical_feats].values, dtype=torch.float32)
x_test_categorical = torch.tensor(test_data[categorical_feats].values, dtype=torch.long)
y_test = torch.tensor(test_data['claims'].values, dtype=torch.float32)
exposure_test = torch.tensor(test_data['expo'].values, dtype=torch.float32)
model.eval()
with torch.no_grad():
y_test_pred = model(x_test_numerical, x_test_categorical)
# Calculate the test loss
# test_loss = criterion(y_test_pred.squeeze() * exposure_test, y_test * exposure_test)
test_loss = (criterion(y_test_pred.squeeze(), y_test) * exposure_test).sum() / exposure_test.sum()
test_rmse = torch.sqrt(test_loss.item() / torch.tensor(len(test_data)))
print(f'Test RMSE: {test_rmse:.4f}')
Test RMSE: 0.0007
This code fits a feedforward neural network with embeddings on categorical features and one hidden layer using PyTorch. It uses early stopping to prevent overfitting and achieves predictions for the response column “claims” in a tabular dataset.
Let us run some diagnostics on this model, on the validation data:
y_val_pred = model(x_val_numerical, x_val_categorical)
val_data["predicted"] = y_val_pred.cpu().detach().numpy().ravel() * val_data.expo
val_data["trueclaims"] = val_data.truefreq * val_data.expo
fig, axs = plt.subplots(len(numerical_feats) + 1, sharex=False, sharey=True, figsize=(7, 40))
for i, f in enumerate(["predicted"] + numerical_feats):
dat_copy = val_data.copy()
dat_copy["decile"] = pd.qcut(dat_copy[f], 10, labels=False, duplicates='drop')
X_sum = dat_copy.groupby("decile").agg("sum").reset_index()
axs[i].plot(X_sum.index, X_sum.trueclaims / X_sum.expo)
axs[i].plot(X_sum.index, X_sum.predicted / X_sum.expo)
axs[i].set_title(f)
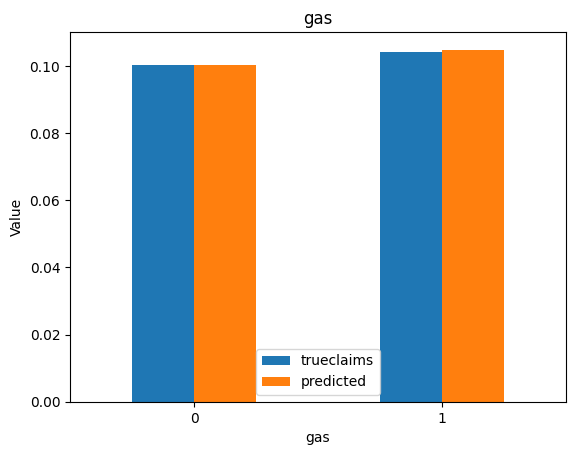
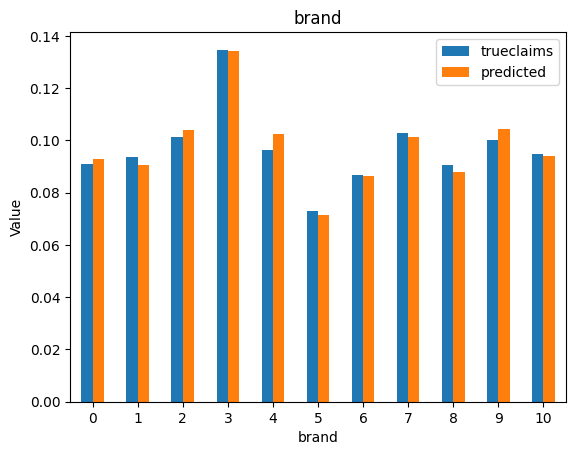
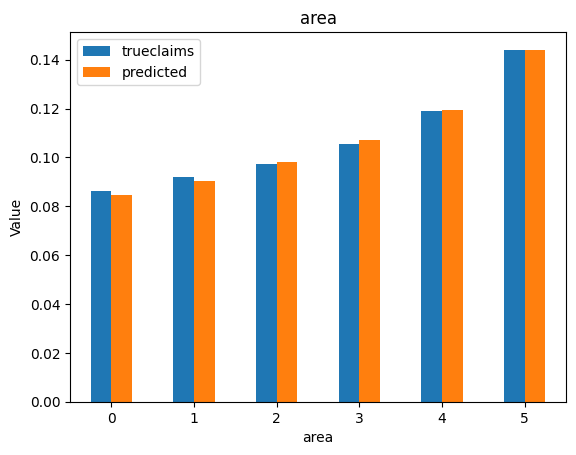
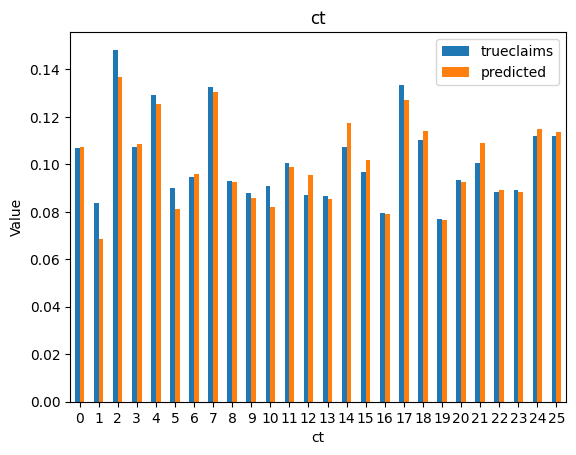
for i, f in enumerate(categorical_feats):
dat_copy = val_data.copy()
X_sum = dat_copy.groupby(f).agg("sum")[["trueclaims", "predicted", "expo"]]
X_sum["trueclaims"] = X_sum["trueclaims"]/X_sum["expo"]
X_sum["predicted"] = X_sum["predicted"]/X_sum["expo"]
X_sum = X_sum.drop(columns="expo")
axs[i] = X_sum.plot(kind='bar', rot=0, xlabel=f, ylabel='Value', title=f)

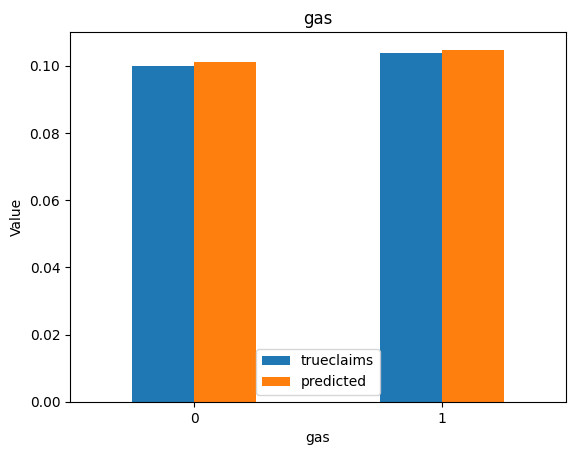
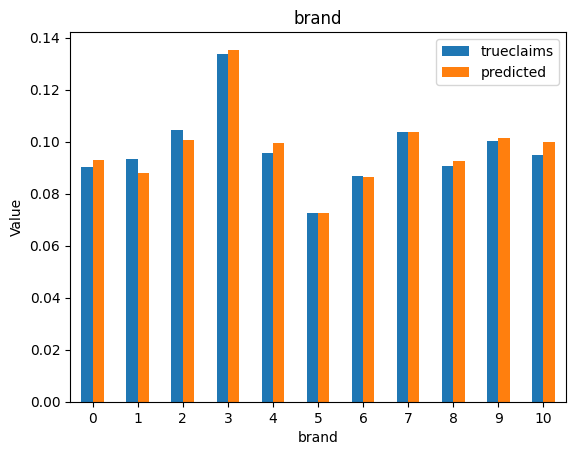
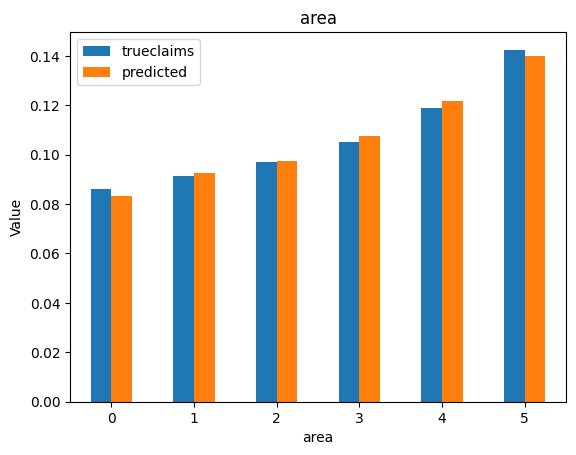
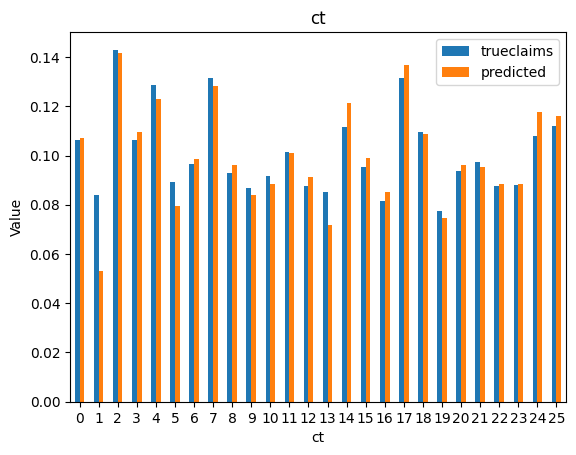
So we have a working model with the assistance of ChatGPT. The code suggestions by the model were generally good, but sometimes subtlely wrong. We still needed an understanding of the mechanics of fitting a neural network on tabular data in order to debug the code generated by the LLM, and to recognise and include any requirements missed in our original prompt. Overall, use of generative AI made the development of this notebook considerably faster.
Onto the experiment on bias:
Experiment on Bias#
We run the training loop 50 times to get a model. We check whether the model predicts an average frequency that matches the (1) training set on which it was fitted and (2) the true underlying frequency. We resample train/test each time so that the sampling does not skew the result.
results = []
weight_list = []
for i in range(0, num_models):
# Resample - Split the dataset into training and validation sets
train_data, val_data = train_test_split(data, test_size=0.2)
for feat in categorical_feats:
train_data[feat] = label_encoders[feat].transform(train_data[feat])
val_data[feat] = label_encoders[feat].transform(val_data[feat])
for feat in numerical_feats:
scaler[feat] = MinMaxScaler()
train_data[feat] = scaler[feat].fit_transform(train_data[feat].values.reshape(-1, 1))
val_data[feat] = scaler[feat].transform(val_data[feat].values.reshape(-1, 1))
# Convert the dataset to PyTorch tensors
x_train_numerical = torch.tensor(train_data[numerical_feats].values, dtype=torch.float32)
x_train_categorical = torch.tensor(train_data[categorical_feats].values, dtype=torch.long)
# y_train = torch.tensor(train_data['claims'].values, dtype=torch.float32)
y_train = torch.tensor(train_data['claims'].values / train_data['expo'].values, dtype=torch.float32)
exposure_train = torch.tensor(train_data['expo'].values, dtype=torch.float32)
x_val_numerical = torch.tensor(val_data[numerical_feats].values, dtype=torch.float32)
x_val_categorical = torch.tensor(val_data[categorical_feats].values, dtype=torch.long)
# y_val = torch.tensor(val_data['claims'].values, dtype=torch.float32)
y_val = torch.tensor(val_data['claims'].values / val_data['expo'].values, dtype=torch.float32)
exposure_val = torch.tensor(val_data['expo'].values, dtype=torch.float32)
# Create an instance of the FeedForwardNet model
model = FeedForwardNet(len(numerical_feats), len(categorical_feats), embedding_sizes, hidden_size, init_bias = np.log(avg_claim).astype(np.float32))
criterion = nn.PoissonNLLLoss(reduction='none', log_input=False)
# Define the optimizer
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
# Train the model
best_val_loss = np.inf
best_epoch = 0
for epoch in range(num_epochs):
model.train()
optimizer.zero_grad()
y_pred = model(x_train_numerical, x_train_categorical)
# loss = criterion(y_pred.squeeze() * exposure_train, y_train * exposure_train)
loss = (criterion(y_pred.squeeze(), y_train) * exposure_train).sum() / exposure_train.sum()
loss.backward()
optimizer.step()
model.eval()
with torch.no_grad():
y_val_pred = model(x_val_numerical, x_val_categorical)
# val_loss = criterion(y_val_pred.squeeze() * exposure_val, y_val * exposure_val)
val_loss = (criterion(y_val_pred.squeeze(), y_val) * exposure_val).sum() / exposure_val.sum()
if val_loss < best_val_loss:
best_val_loss = val_loss
best_epoch = epoch
best_weights = model.state_dict().copy()
torch.save(best_weights, 'best_model.pt')
best_result = {
"Epoch": epoch,
"Train_Diff": ((y_pred.squeeze() * exposure_train - y_train * exposure_train).sum() / exposure_train.sum()).item(),
"Train_Mean": ((y_pred.squeeze() * exposure_train).sum() / exposure_train.sum()).item(),
"Train_Loss": loss.item(),
"Val_mean": ((y_val_pred.squeeze() * exposure_val).sum() / exposure_val.sum()).item(),
"Val_loss": val_loss.item(),
"Mean": 0.8*((y_pred.squeeze() * exposure_train).sum() / exposure_train.sum()).item() + 0.2*((y_val_pred.squeeze() * exposure_val).sum() / exposure_val.sum()).item()
}
if epoch - best_epoch >= early_stopping_epochs:
results += [best_result]
break
weight_list.append(best_weights)
pd.DataFrame(results)
| Epoch | Train_Diff | Train_Mean | Train_Loss | Val_mean | Val_loss | Mean | |
|---|---|---|---|---|---|---|---|
| 0 | 130 | -0.000645 | 0.102177 | 0.325923 | 0.100916 | 0.326849 | 0.101925 |
| 1 | 112 | 0.001128 | 0.104126 | 0.326204 | 0.100970 | 0.325138 | 0.103495 |
| 2 | 100 | -0.011181 | 0.091365 | 0.329277 | 0.104439 | 0.330272 | 0.093980 |
| 3 | 144 | 0.003659 | 0.106545 | 0.326212 | 0.101356 | 0.326794 | 0.105507 |
| 4 | 149 | -0.001328 | 0.100622 | 0.323909 | 0.103777 | 0.334216 | 0.101253 |
| 5 | 143 | -0.000898 | 0.101453 | 0.325552 | 0.102908 | 0.330316 | 0.101744 |
| 6 | 121 | -0.002593 | 0.099565 | 0.324868 | 0.103678 | 0.332443 | 0.100387 |
| 7 | 99 | 0.004969 | 0.107395 | 0.325997 | 0.101939 | 0.330895 | 0.106304 |
| 8 | 175 | -0.001557 | 0.101031 | 0.324581 | 0.102687 | 0.328301 | 0.101362 |
| 9 | 103 | -0.001491 | 0.101537 | 0.326496 | 0.101486 | 0.325832 | 0.101527 |
| 10 | 129 | -0.000352 | 0.101937 | 0.324772 | 0.103736 | 0.331179 | 0.102297 |
| 11 | 119 | -0.000176 | 0.102137 | 0.325486 | 0.103809 | 0.330387 | 0.102471 |
| 12 | 100 | -0.011435 | 0.091064 | 0.327402 | 0.103818 | 0.329969 | 0.093615 |
| 13 | 151 | 0.001976 | 0.105372 | 0.326752 | 0.100252 | 0.321554 | 0.104348 |
| 14 | 114 | -0.012920 | 0.089249 | 0.327542 | 0.104257 | 0.332765 | 0.092251 |
| 15 | 119 | -0.004242 | 0.098700 | 0.326383 | 0.101354 | 0.326429 | 0.099231 |
| 16 | 117 | 0.002508 | 0.104865 | 0.324898 | 0.101881 | 0.331432 | 0.104268 |
| 17 | 111 | -0.001113 | 0.101655 | 0.326419 | 0.101905 | 0.327278 | 0.101705 |
| 18 | 86 | 0.019172 | 0.122249 | 0.330964 | 0.102479 | 0.325229 | 0.118295 |
| 19 | 170 | 0.000330 | 0.103443 | 0.326102 | 0.101849 | 0.324363 | 0.103124 |
| 20 | 136 | -0.002997 | 0.099309 | 0.324692 | 0.103050 | 0.332011 | 0.100057 |
| 21 | 124 | -0.002397 | 0.100309 | 0.326027 | 0.102895 | 0.327030 | 0.100826 |
| 22 | 127 | 0.001637 | 0.104221 | 0.325922 | 0.103401 | 0.328156 | 0.104057 |
| 23 | 109 | 0.003718 | 0.106884 | 0.327108 | 0.101984 | 0.324299 | 0.105904 |
| 24 | 104 | 0.006168 | 0.108760 | 0.326227 | 0.100372 | 0.330046 | 0.107083 |
| 25 | 124 | -0.000329 | 0.102373 | 0.325716 | 0.102718 | 0.327641 | 0.102442 |
| 26 | 104 | 0.004465 | 0.107011 | 0.325303 | 0.101300 | 0.329909 | 0.105869 |
| 27 | 97 | 0.003505 | 0.106148 | 0.326087 | 0.102803 | 0.328730 | 0.105479 |
| 28 | 152 | 0.003044 | 0.106007 | 0.325944 | 0.101053 | 0.325613 | 0.105016 |
| 29 | 119 | 0.000471 | 0.103239 | 0.325658 | 0.101029 | 0.328178 | 0.102797 |
| 30 | 105 | -0.010499 | 0.092104 | 0.327594 | 0.102481 | 0.329511 | 0.094180 |
| 31 | 101 | 0.000356 | 0.103143 | 0.326779 | 0.101786 | 0.328151 | 0.102872 |
| 32 | 97 | -0.007540 | 0.094523 | 0.325637 | 0.106127 | 0.335037 | 0.096844 |
| 33 | 110 | -0.007851 | 0.094789 | 0.326994 | 0.103555 | 0.327416 | 0.096542 |
| 34 | 130 | 0.007680 | 0.110865 | 0.327033 | 0.102342 | 0.324362 | 0.109160 |
| 35 | 106 | -0.000806 | 0.101983 | 0.325870 | 0.102793 | 0.326325 | 0.102145 |
| 36 | 116 | 0.001485 | 0.104698 | 0.326662 | 0.101559 | 0.323815 | 0.104070 |
| 37 | 107 | 0.001997 | 0.104687 | 0.325665 | 0.104222 | 0.328122 | 0.104594 |
| 38 | 90 | -0.002557 | 0.100565 | 0.327322 | 0.102357 | 0.325118 | 0.100923 |
| 39 | 141 | 0.003426 | 0.106498 | 0.325961 | 0.099360 | 0.324842 | 0.105071 |
| 40 | 121 | -0.002862 | 0.099332 | 0.324686 | 0.103656 | 0.332309 | 0.100197 |
| 41 | 87 | -0.008324 | 0.094025 | 0.327252 | 0.102607 | 0.331421 | 0.095741 |
| 42 | 119 | -0.000314 | 0.101241 | 0.323135 | 0.107160 | 0.337909 | 0.102425 |
| 43 | 164 | -0.000449 | 0.101789 | 0.324233 | 0.102688 | 0.331431 | 0.101968 |
| 44 | 136 | -0.001592 | 0.100898 | 0.324840 | 0.102806 | 0.329460 | 0.101279 |
| 45 | 111 | -0.003606 | 0.098748 | 0.325302 | 0.105494 | 0.330357 | 0.100097 |
| 46 | 203 | -0.002093 | 0.100181 | 0.324759 | 0.105140 | 0.330792 | 0.101173 |
| 47 | 158 | 0.000963 | 0.103939 | 0.325994 | 0.101919 | 0.325458 | 0.103535 |
| 48 | 107 | -0.008366 | 0.095289 | 0.330197 | 0.103185 | 0.320212 | 0.096868 |
| 49 | 120 | -0.004596 | 0.097606 | 0.325099 | 0.105453 | 0.331423 | 0.099175 |
So, are our 50 neural networks making biased predictions vs their training sets?
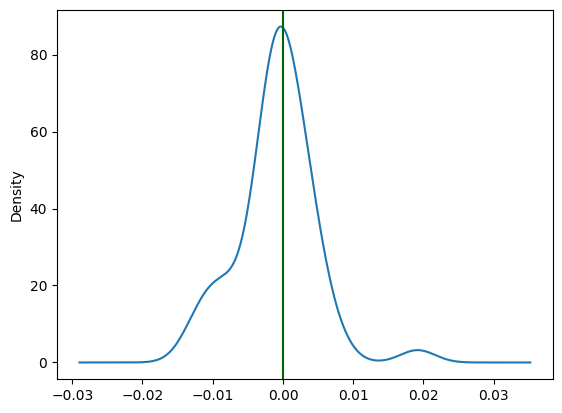
pd.DataFrame(results).Train_Diff.plot.kde()
plt.axvline(x = 0.0, color = 'darkgreen')
<matplotlib.lines.Line2D at 0x2bf030070>
bias_std = pd.DataFrame(results).Train_Diff.std()
pd.DataFrame(results).Train_Diff.mean(), pd.DataFrame(results).Train_Diff.std()
(-0.0008891218338976614, 0.005435967840328695)
Training runs do appear to match on average, the mean frequency of the training dataset. However early stopping appears to lead to models that are sometimes predicting higher and sometimes predicting lower.
How does the model go in matching the true and dataset means?
pd.DataFrame(results).Mean.plot.kde()
plt.axvline(x = avg_claim, color = 'darkgreen')
<matplotlib.lines.Line2D at 0x2bf0339d0>
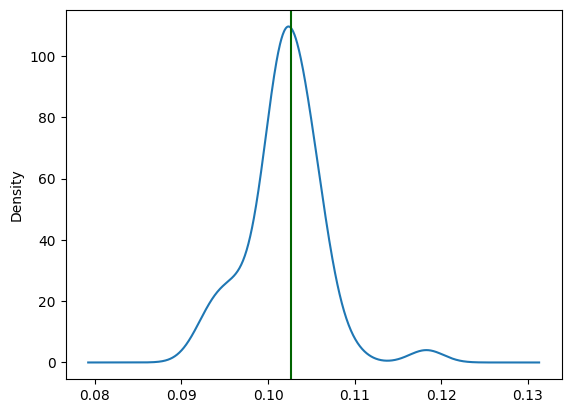
Models predict near the mean values, but there is some variabilty of the predictions around it.
Overall, with help from ChatGPT, we appear to have replicated the finding from the Wuthrich paper that early stopping can lead to the biased models. On average, models predict at near the correct average levels, but individual models may predict with some variability around that level - they are biased. None of this is new or original but ChatGPT was quite helpful in being to recreate this analysis in Python (Wuthrich appears to have used R).
Currently our average validation loss is:
avg_val_loss = pd.DataFrame(results).Val_loss.mean()
avg_val_loss
0.32853454232215884
Solving the bias issue#
Wuthrich suggests regularization approaches to reduce the bias. See Section 4 in his paper.
Wuthrich in his other work also discusses ensembling approach in Section 5.1.6. Here the 50 models have a variability in the overall predicted levels, but on average they are right. So if we were to take the final model as the ensemble average of the 50 models, it would average out the bias issue.
# Average neural network prediction:
avg_nn_prediction = pd.DataFrame(results).Mean.mean()
# Average frequency in dataset
avg_frequency = data['claims'].values.sum() / data['expo'].values.sum()
# True underlying frequency
true_frequency = (data['truefreq'] * data['expo']).values.sum() / data['expo'].values.sum()
print("Average neural network prediction:", avg_nn_prediction)
print("Average frequency in dataset:", avg_frequency)
print("True underlying frequency:", true_frequency)
print("Averaged prediction vs true frequency:", avg_nn_prediction / true_frequency)
Average neural network prediction: 0.10194956490397454
Average frequency in dataset: 0.10269062235781508
True underlying frequency: 0.10199107887858037
Averaged prediction vs true frequency: 0.9995929646488468
Learn Rates#
Another idea from other neural network work is to apply a higher learn rate solely on the bias.
The idea is to allow the bias to converge on its true value faster, before the other weights begin to overfit, triggering the early stopping and halting training.
hidden_size = [20, 15, 10] # Replace with the multi-layer parameters.
num_epochs = 99999 # should not be a factor, we train until early stopping kicks in
early_stopping_epochs = 10
learning_rate = 0.005 # Half base learning rate
bias_learning_rate = 0.05 # Increased bias learning rate
The training loop is updated with the optimizer applying this higher learning rate to the one bias value.
results = []
weight_list = []
for i in range(0, num_models):
# Resample - Split the dataset into training and validation sets
train_data, val_data = train_test_split(data, test_size=0.2)
for feat in categorical_feats:
train_data[feat] = label_encoders[feat].transform(train_data[feat])
val_data[feat] = label_encoders[feat].transform(val_data[feat])
for feat in numerical_feats:
scaler[feat] = MinMaxScaler()
train_data[feat] = scaler[feat].fit_transform(train_data[feat].values.reshape(-1, 1))
val_data[feat] = scaler[feat].transform(val_data[feat].values.reshape(-1, 1))
# Convert the dataset to PyTorch tensors
x_train_numerical = torch.tensor(train_data[numerical_feats].values, dtype=torch.float32)
x_train_categorical = torch.tensor(train_data[categorical_feats].values, dtype=torch.long)
# y_train = torch.tensor(train_data['claims'].values, dtype=torch.float32)
y_train = torch.tensor(train_data['claims'].values / train_data['expo'].values, dtype=torch.float32)
exposure_train = torch.tensor(train_data['expo'].values, dtype=torch.float32)
x_val_numerical = torch.tensor(val_data[numerical_feats].values, dtype=torch.float32)
x_val_categorical = torch.tensor(val_data[categorical_feats].values, dtype=torch.long)
# y_val = torch.tensor(val_data['claims'].values, dtype=torch.float32)
y_val = torch.tensor(val_data['claims'].values / val_data['expo'].values, dtype=torch.float32)
exposure_val = torch.tensor(val_data['expo'].values, dtype=torch.float32)
# Create an instance of the FeedForwardNet model
model = FeedForwardNet(len(numerical_feats), len(categorical_feats), embedding_sizes, hidden_size, init_bias = np.log(avg_claim).astype(np.float32))
criterion = nn.PoissonNLLLoss(reduction='none', log_input=False)
# Bias specific learn rates
my_list = ['fc2.bias']
bias_params = list(filter(lambda kv: kv[0] in my_list, model.named_parameters()))
base_params = list(filter(lambda kv: kv[0] not in my_list, model.named_parameters()))
# Define the optimizer
# optimizer = optim.Adam(model.parameters(), lr=learning_rate)
optimizer = optim.Adam([
{'params': [temp[1] for temp in base_params]},
{'params': [temp[1] for temp in bias_params], 'lr': bias_learning_rate}
], lr=learning_rate)
# Train the model
best_val_loss = np.inf
best_epoch = 0
for epoch in range(num_epochs):
model.train()
optimizer.zero_grad()
y_pred = model(x_train_numerical, x_train_categorical)
# loss = criterion(y_pred.squeeze() * exposure_train, y_train * exposure_train)
loss = (criterion(y_pred.squeeze(), y_train) * exposure_train).sum() / exposure_train.sum()
loss.backward()
optimizer.step()
model.eval()
with torch.no_grad():
y_val_pred = model(x_val_numerical, x_val_categorical)
# val_loss = criterion(y_val_pred.squeeze() * exposure_val, y_val * exposure_val)
val_loss = (criterion(y_val_pred.squeeze(), y_val) * exposure_val).sum() / exposure_val.sum()
if val_loss < best_val_loss:
best_val_loss = val_loss
best_epoch = epoch
best_weights = model.state_dict().copy()
torch.save(best_weights, 'best_model.pt')
best_result = {
"Epoch": epoch,
"Train_Diff": ((y_pred.squeeze() * exposure_train - y_train * exposure_train).sum() / exposure_train.sum()).item(),
"Train_Mean": ((y_pred.squeeze() * exposure_train).sum() / exposure_train.sum()).item(),
"Train_Loss": loss.item(),
"Val_mean": ((y_val_pred.squeeze() * exposure_val).sum() / exposure_val.sum()).item(),
"Val_loss": val_loss.item(),
"Mean": 0.8*((y_pred.squeeze() * exposure_train).sum() / exposure_train.sum()).item() + 0.2*((y_val_pred.squeeze() * exposure_val).sum() / exposure_val.sum()).item()
}
if epoch - best_epoch >= early_stopping_epochs:
results += [best_result]
break
weight_list.append(best_weights)
# check we have the right parameter
bias_params
[('fc2.bias',
Parameter containing:
tensor(-2.1823, requires_grad=True))]
So how do results look with this?
pd.DataFrame(results)
| Epoch | Train_Diff | Train_Mean | Train_Loss | Val_mean | Val_loss | Mean | |
|---|---|---|---|---|---|---|---|
| 0 | 205 | 0.002327 | 0.104974 | 0.325422 | 0.101117 | 0.328724 | 0.104203 |
| 1 | 168 | 0.000035 | 0.102497 | 0.325165 | 0.101048 | 0.330128 | 0.102208 |
| 2 | 208 | 0.001107 | 0.103627 | 0.324849 | 0.102306 | 0.330064 | 0.103363 |
| 3 | 194 | -0.002439 | 0.100004 | 0.325384 | 0.104841 | 0.329106 | 0.100971 |
| 4 | 216 | -0.002707 | 0.099631 | 0.324795 | 0.104469 | 0.329759 | 0.100599 |
| 5 | 155 | -0.004103 | 0.098337 | 0.325339 | 0.103473 | 0.330643 | 0.099364 |
| 6 | 173 | 0.001059 | 0.104135 | 0.326621 | 0.102555 | 0.323889 | 0.103819 |
| 7 | 239 | 0.000795 | 0.103905 | 0.325969 | 0.101931 | 0.323872 | 0.103510 |
| 8 | 219 | -0.000637 | 0.102157 | 0.325523 | 0.102171 | 0.325915 | 0.102160 |
| 9 | 168 | 0.002321 | 0.105407 | 0.326163 | 0.101906 | 0.324060 | 0.104707 |
| 10 | 143 | 0.000277 | 0.103440 | 0.327099 | 0.103935 | 0.323553 | 0.103539 |
| 11 | 138 | -0.003321 | 0.099526 | 0.326536 | 0.104895 | 0.325924 | 0.100600 |
| 12 | 139 | -0.002427 | 0.099488 | 0.324715 | 0.105711 | 0.334265 | 0.100732 |
| 13 | 155 | -0.002495 | 0.100064 | 0.325782 | 0.104031 | 0.328607 | 0.100857 |
| 14 | 176 | -0.000415 | 0.102324 | 0.326006 | 0.103674 | 0.326932 | 0.102594 |
| 15 | 208 | 0.002315 | 0.104998 | 0.325499 | 0.102390 | 0.327024 | 0.104476 |
| 16 | 214 | 0.001363 | 0.104500 | 0.326591 | 0.102777 | 0.324041 | 0.104155 |
| 17 | 150 | 0.001920 | 0.104772 | 0.326084 | 0.101824 | 0.325707 | 0.104182 |
| 18 | 160 | -0.002173 | 0.100638 | 0.326172 | 0.102994 | 0.325890 | 0.101109 |
| 19 | 183 | 0.000192 | 0.103026 | 0.325667 | 0.101727 | 0.326649 | 0.102766 |
| 20 | 180 | -0.000990 | 0.101203 | 0.325036 | 0.103650 | 0.331248 | 0.101692 |
| 21 | 197 | -0.001338 | 0.100844 | 0.324968 | 0.104099 | 0.331851 | 0.101495 |
| 22 | 164 | 0.001723 | 0.104569 | 0.326951 | 0.100148 | 0.328108 | 0.103685 |
| 23 | 207 | 0.003274 | 0.105323 | 0.323811 | 0.103895 | 0.333068 | 0.105037 |
| 24 | 166 | 0.002680 | 0.105871 | 0.326872 | 0.101878 | 0.322789 | 0.105072 |
| 25 | 180 | 0.000940 | 0.103496 | 0.325236 | 0.103305 | 0.328780 | 0.103458 |
| 26 | 201 | -0.000276 | 0.102151 | 0.324925 | 0.101921 | 0.329467 | 0.102105 |
| 27 | 177 | -0.000592 | 0.102395 | 0.326053 | 0.101323 | 0.325711 | 0.102180 |
| 28 | 215 | 0.002475 | 0.105416 | 0.326046 | 0.100961 | 0.325818 | 0.104525 |
| 29 | 171 | -0.001479 | 0.100942 | 0.325523 | 0.103197 | 0.330104 | 0.101393 |
| 30 | 230 | -0.000927 | 0.101362 | 0.324933 | 0.103380 | 0.330297 | 0.101765 |
| 31 | 162 | 0.001179 | 0.103946 | 0.326290 | 0.102380 | 0.327654 | 0.103633 |
| 32 | 183 | 0.002927 | 0.105697 | 0.325705 | 0.101642 | 0.327327 | 0.104886 |
| 33 | 194 | 0.001614 | 0.103999 | 0.325319 | 0.102904 | 0.330006 | 0.103780 |
| 34 | 170 | 0.002754 | 0.105223 | 0.325185 | 0.101073 | 0.330482 | 0.104393 |
| 35 | 144 | -0.002177 | 0.100043 | 0.325104 | 0.102772 | 0.331401 | 0.100589 |
| 36 | 212 | 0.000414 | 0.102930 | 0.325115 | 0.101467 | 0.328294 | 0.102637 |
| 37 | 173 | -0.000467 | 0.102793 | 0.326599 | 0.103692 | 0.322864 | 0.102973 |
| 38 | 200 | -0.001061 | 0.101328 | 0.325358 | 0.102929 | 0.329955 | 0.101648 |
| 39 | 196 | -0.002276 | 0.100090 | 0.325243 | 0.103280 | 0.330101 | 0.100728 |
| 40 | 201 | 0.000618 | 0.103018 | 0.324686 | 0.101520 | 0.331242 | 0.102718 |
| 41 | 188 | 0.001549 | 0.104363 | 0.325910 | 0.102523 | 0.326799 | 0.103995 |
| 42 | 128 | 0.002517 | 0.105386 | 0.326826 | 0.101684 | 0.326658 | 0.104645 |
| 43 | 150 | 0.002720 | 0.106185 | 0.327632 | 0.101504 | 0.321514 | 0.105249 |
| 44 | 202 | -0.000765 | 0.101599 | 0.325121 | 0.103453 | 0.330568 | 0.101969 |
| 45 | 195 | -0.007928 | 0.094683 | 0.326373 | 0.103778 | 0.328316 | 0.096502 |
| 46 | 179 | -0.002498 | 0.099990 | 0.325483 | 0.103390 | 0.329075 | 0.100670 |
| 47 | 177 | -0.002789 | 0.099647 | 0.325664 | 0.103856 | 0.328823 | 0.100489 |
| 48 | 163 | 0.002125 | 0.104693 | 0.325735 | 0.102967 | 0.327648 | 0.104348 |
| 49 | 237 | -0.000325 | 0.102494 | 0.325931 | 0.104136 | 0.325074 | 0.102823 |
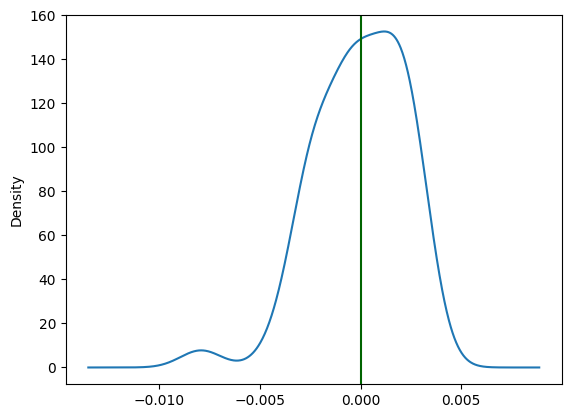
pd.DataFrame(results).Train_Diff.plot.kde()
plt.axvline(x = 0.0, color = 'darkgreen')
<matplotlib.lines.Line2D at 0x2c01e7e50>
new_bias_std = pd.DataFrame(results).Train_Diff.std()
pd.DataFrame(results).Train_Diff.mean(), pd.DataFrame(results).Train_Diff.std()
(-6.771093656425364e-05, 0.0022470243173901318)
Compare the standard deviation of the bias with the bias-specific learning rate compared with the same learning rate across both.
new_bias_std / bias_std
0.41336232726024763
We can see with the abve result that the increased bias-specific learn rate was successful in reducing the variance in the overall model bias.
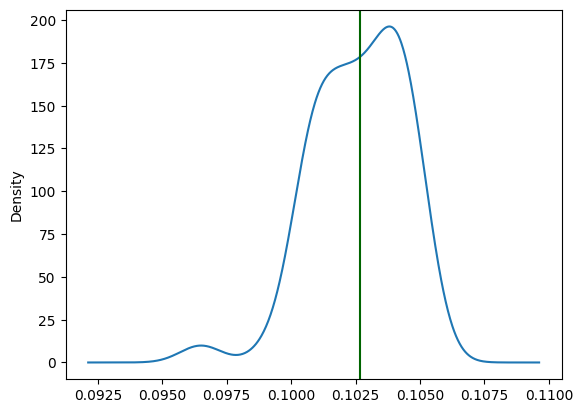
pd.DataFrame(results).Mean.plot.kde()
plt.axvline(x = avg_claim, color = 'darkgreen')
<matplotlib.lines.Line2D at 0x2c4911a80>
(
# Average neural network prediction:
pd.DataFrame(results).Mean.mean(),
# Average frequency in dataset
data['claims'].values.sum() / data['expo'].values.sum(),
# True underlying frequency
(data['truefreq'] * data['expo']).values.sum() / data['expo'].values.sum(),
)
(0.10261997532844544, 0.10269062235781508, 0.10199107887858037)
Predicted mean frequency for the models look to track near the training data mean more consistently.
Finally, the validation loss. Unlike regularisation, which is known to shape the segmentation predictions, conceptually a higher learn rate for the bias should just mean the training loop focuses on getting a more aligned bias estimate. Does this come through in our result?
fast_bias_val_loss = pd.DataFrame(results).Val_loss.mean()
fast_bias_val_loss
0.32791590332984927
fast_bias_val_loss - avg_val_loss
-0.0006186389923095725
The experiments are random so results may vary if this is re-run but for this run, val loss was similar.
Look at the diagnostics again. This will be on the last model of the batch that was trained.
# Load the best model in the last run
model.load_state_dict(torch.load('best_model.pt'))
y_val_pred = model(x_val_numerical, x_val_categorical)
val_data["predicted"] = y_val_pred.cpu().detach().numpy().ravel() * val_data.expo
val_data["trueclaims"] = val_data.truefreq * val_data.expo
fig, axs = plt.subplots(len(numerical_feats) + 1, sharex=False, sharey=True, figsize=(7, 40))
for i, f in enumerate(["predicted"] + numerical_feats):
dat_copy = val_data.copy()
dat_copy["decile"] = pd.qcut(dat_copy[f], 10, labels=False, duplicates='drop')
X_sum = dat_copy.groupby("decile").agg("sum").reset_index()
axs[i].plot(X_sum.index, X_sum.trueclaims / X_sum.expo)
axs[i].plot(X_sum.index, X_sum.predicted / X_sum.expo)
axs[i].set_title(f)
for i, f in enumerate(categorical_feats):
dat_copy = val_data.copy()
X_sum = dat_copy.groupby(f).agg("sum")[["trueclaims", "predicted", "expo"]]
X_sum["trueclaims"] = X_sum["trueclaims"]/X_sum["expo"]
X_sum["predicted"] = X_sum["predicted"]/X_sum["expo"]
X_sum = X_sum.drop(columns="expo")
axs[i] = X_sum.plot(kind='bar', rot=0, xlabel=f, ylabel='Value', title=f)

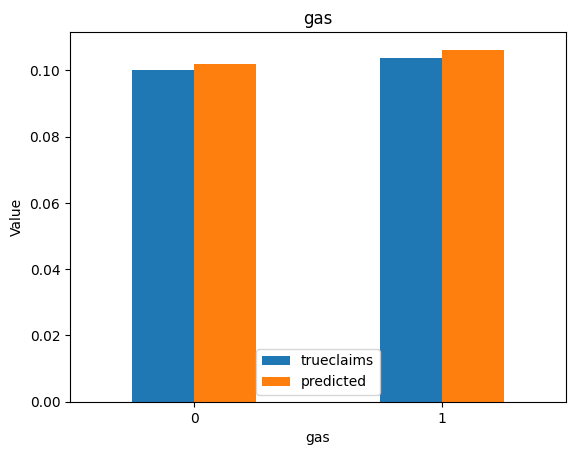
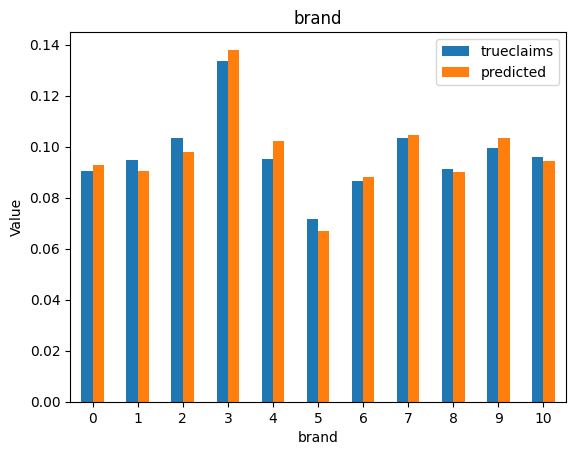
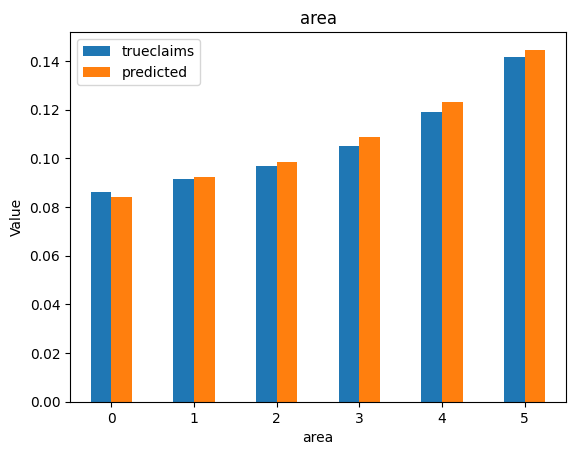
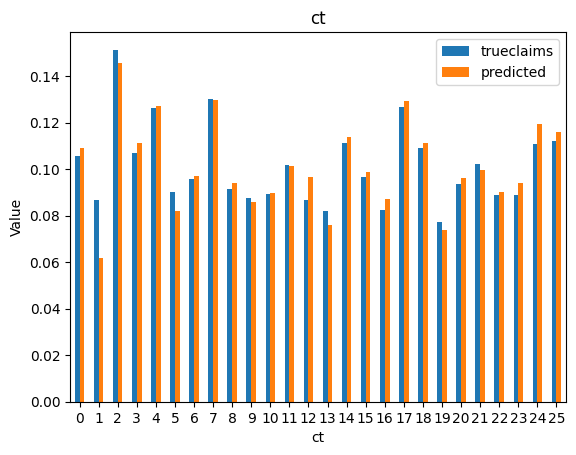
Diagnostics still look good.
Just change the bias#
In Wuthrich 2023, he proposes (Section 5.1.5) the idea of training a GLM to full convergence with the final hidden layer weights and biases from the neural network to solve the bias issue.
Finally, if having an unbiased model with early stopping is a must have, with pytorch we have full control over the training loop.
We could just explicitly set bias after every epoch to the value that keeps the predicted mean to be the mean of the training data.
# Define the hyperparameters
hidden_size = [20, 15, 10] # Replace with the multi-layer parameters.
learning_rate = 0.01
num_epochs = 9999 # should not be a factor, we train until early stopping kicks in
early_stopping_epochs = 10
results = []
weight_list = []
for i in range(0, num_models):
# Resample - Split the dataset into training and validation sets
train_data, val_data = train_test_split(data, test_size=0.2)
for feat in categorical_feats:
train_data[feat] = label_encoders[feat].transform(train_data[feat])
val_data[feat] = label_encoders[feat].transform(val_data[feat])
for feat in numerical_feats:
scaler[feat] = MinMaxScaler()
train_data[feat] = scaler[feat].fit_transform(train_data[feat].values.reshape(-1, 1))
val_data[feat] = scaler[feat].transform(val_data[feat].values.reshape(-1, 1))
# Convert the dataset to PyTorch tensors
x_train_numerical = torch.tensor(train_data[numerical_feats].values, dtype=torch.float32)
x_train_categorical = torch.tensor(train_data[categorical_feats].values, dtype=torch.long)
y_train = torch.tensor(train_data['claims'].values / train_data['expo'].values, dtype=torch.float32)
exposure_train = torch.tensor(train_data['expo'].values, dtype=torch.float32)
x_val_numerical = torch.tensor(val_data[numerical_feats].values, dtype=torch.float32)
x_val_categorical = torch.tensor(val_data[categorical_feats].values, dtype=torch.long)
y_val = torch.tensor(val_data['claims'].values / val_data['expo'].values, dtype=torch.float32)
exposure_val = torch.tensor(val_data['expo'].values, dtype=torch.float32)
# Create an instance of the FeedForwardNet model
model = FeedForwardNet(len(numerical_feats), len(categorical_feats), embedding_sizes, hidden_size, init_bias = np.log(avg_claim).astype(np.float32))
criterion = nn.PoissonNLLLoss(reduction='none', log_input=False)
# Define the optimizer
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
# Train the model
best_val_loss = np.inf
best_epoch = 0
for epoch in range(num_epochs):
model.train()
optimizer.zero_grad()
y_pred = model(x_train_numerical, x_train_categorical)
loss = (criterion(y_pred.squeeze(), y_train) * exposure_train).sum() / exposure_train.sum()
loss.backward()
optimizer.step()
model.eval()
# Adjust the bias each epoch
with torch.no_grad():
# Get predictions
y_pred = model(x_train_numerical, x_train_categorical)
# Get adjustment
adjustment = torch.log((y_train * exposure_train).sum()) - torch.log((y_pred.squeeze() * exposure_train).sum())
model.fc2.bias.data += adjustment
# Adjusted y_pred
y_pred = model(x_train_numerical, x_train_categorical)
with torch.no_grad():
y_val_pred = model(x_val_numerical, x_val_categorical)
val_loss = (criterion(y_val_pred.squeeze(), y_val) * exposure_val).sum() / exposure_val.sum()
if val_loss < best_val_loss:
best_val_loss = val_loss
best_epoch = epoch
best_weights = model.state_dict().copy()
torch.save(best_weights, 'best_model.pt')
best_result = {
"Epoch": epoch,
"Train_Diff": ((y_pred.squeeze() * exposure_train - y_train * exposure_train).sum() / exposure_train.sum()).item(),
"Train_Mean": ((y_pred.squeeze() * exposure_train).sum() / exposure_train.sum()).item(),
"Train_Loss": loss.item(),
"Val_mean": ((y_val_pred.squeeze() * exposure_val).sum() / exposure_val.sum()).item(),
"Val_loss": val_loss.item(),
"Mean": 0.8*((y_pred.squeeze() * exposure_train).sum() / exposure_train.sum()).item() + 0.2*((y_val_pred.squeeze() * exposure_val).sum() / exposure_val.sum()).item()
}
if epoch - best_epoch >= early_stopping_epochs:
results += [best_result]
break
weight_list.append(best_weights)
pd.DataFrame(results)
| Epoch | Train_Diff | Train_Mean | Train_Loss | Val_mean | Val_loss | Mean | |
|---|---|---|---|---|---|---|---|
| 0 | 122 | 2.392140e-09 | 0.102556 | 0.324907 | 0.102498 | 0.328764 | 0.102544 |
| 1 | 97 | -2.860957e-08 | 0.102573 | 0.325711 | 0.102370 | 0.329056 | 0.102533 |
| 2 | 103 | -1.143877e-08 | 0.102153 | 0.324566 | 0.102151 | 0.332670 | 0.102152 |
| 3 | 100 | 2.330167e-08 | 0.103220 | 0.326741 | 0.103121 | 0.323224 | 0.103200 |
| 4 | 114 | 1.104944e-08 | 0.102778 | 0.326044 | 0.103099 | 0.326367 | 0.102842 |
| 5 | 137 | -3.339519e-08 | 0.102181 | 0.324399 | 0.102149 | 0.333316 | 0.102175 |
| 6 | 105 | 5.588781e-08 | 0.102945 | 0.326395 | 0.103071 | 0.325628 | 0.102970 |
| 7 | 151 | -4.614875e-08 | 0.102484 | 0.324409 | 0.102470 | 0.329613 | 0.102481 |
| 8 | 97 | 4.902244e-10 | 0.102397 | 0.325335 | 0.101848 | 0.329740 | 0.102287 |
| 9 | 109 | -5.120140e-08 | 0.102658 | 0.325921 | 0.102671 | 0.328305 | 0.102660 |
| 10 | 116 | -8.096723e-09 | 0.103427 | 0.326815 | 0.103234 | 0.321770 | 0.103388 |
| 11 | 101 | -2.164153e-08 | 0.102033 | 0.324435 | 0.101915 | 0.333433 | 0.102010 |
| 12 | 117 | -3.639235e-08 | 0.102620 | 0.325797 | 0.102445 | 0.328296 | 0.102585 |
| 13 | 112 | -1.901544e-08 | 0.102983 | 0.326010 | 0.103124 | 0.324312 | 0.103011 |
| 14 | 103 | -6.258782e-08 | 0.102355 | 0.324778 | 0.102871 | 0.330884 | 0.102458 |
| 15 | 110 | 3.401983e-08 | 0.102748 | 0.325920 | 0.102963 | 0.325666 | 0.102791 |
| 16 | 111 | -1.676353e-08 | 0.102496 | 0.325475 | 0.102318 | 0.328534 | 0.102460 |
| 17 | 91 | 7.000872e-08 | 0.102985 | 0.326366 | 0.103263 | 0.324911 | 0.103040 |
| 18 | 103 | -4.030646e-08 | 0.102205 | 0.324718 | 0.102024 | 0.331843 | 0.102169 |
| 19 | 99 | 4.145939e-08 | 0.102938 | 0.326770 | 0.103006 | 0.324792 | 0.102952 |
| 20 | 97 | -1.510715e-08 | 0.102897 | 0.326182 | 0.102669 | 0.326991 | 0.102852 |
| 21 | 131 | -5.966714e-08 | 0.101933 | 0.323772 | 0.101948 | 0.334276 | 0.101936 |
| 22 | 120 | -2.709646e-08 | 0.102465 | 0.325010 | 0.102429 | 0.330330 | 0.102458 |
| 23 | 105 | -2.102355e-08 | 0.102337 | 0.325117 | 0.102071 | 0.331128 | 0.102284 |
| 24 | 108 | -4.034199e-08 | 0.102668 | 0.326064 | 0.102556 | 0.327703 | 0.102646 |
| 25 | 119 | -2.227432e-08 | 0.103057 | 0.326187 | 0.102746 | 0.325391 | 0.102994 |
| 26 | 101 | 2.083051e-08 | 0.102695 | 0.326309 | 0.102215 | 0.327150 | 0.102599 |
| 27 | 121 | 1.541380e-08 | 0.102893 | 0.326008 | 0.103202 | 0.325928 | 0.102955 |
| 28 | 113 | 3.449376e-08 | 0.102807 | 0.325954 | 0.102774 | 0.325762 | 0.102800 |
| 29 | 126 | 2.174281e-08 | 0.103070 | 0.326702 | 0.103266 | 0.324199 | 0.103109 |
| 30 | 117 | -1.656592e-08 | 0.102850 | 0.326272 | 0.102875 | 0.327013 | 0.102855 |
| 31 | 129 | 6.832808e-08 | 0.102650 | 0.325482 | 0.102521 | 0.327829 | 0.102624 |
| 32 | 77 | -1.616476e-08 | 0.102999 | 0.326902 | 0.103152 | 0.326036 | 0.103029 |
| 33 | 88 | 5.655543e-09 | 0.102623 | 0.326193 | 0.102884 | 0.329003 | 0.102675 |
| 34 | 162 | -2.356158e-09 | 0.102348 | 0.324156 | 0.102377 | 0.331616 | 0.102353 |
| 35 | 86 | 4.196311e-08 | 0.102868 | 0.327524 | 0.103084 | 0.326439 | 0.102911 |
| 36 | 89 | -5.090045e-08 | 0.101892 | 0.324506 | 0.102245 | 0.334591 | 0.101962 |
| 37 | 108 | 2.277418e-08 | 0.102124 | 0.324321 | 0.102444 | 0.332908 | 0.102188 |
| 38 | 116 | 6.947347e-08 | 0.102534 | 0.325019 | 0.102408 | 0.329999 | 0.102509 |
| 39 | 80 | 7.592326e-08 | 0.102538 | 0.326241 | 0.102415 | 0.328567 | 0.102514 |
| 40 | 111 | -1.581654e-08 | 0.102781 | 0.326168 | 0.102739 | 0.326581 | 0.102772 |
| 41 | 98 | 5.042758e-08 | 0.102842 | 0.326228 | 0.102668 | 0.326550 | 0.102807 |
| 42 | 87 | 8.698981e-08 | 0.102296 | 0.325354 | 0.101990 | 0.332758 | 0.102235 |
| 43 | 123 | 6.307235e-08 | 0.103129 | 0.326391 | 0.102828 | 0.323361 | 0.103069 |
| 44 | 102 | 2.011095e-08 | 0.102592 | 0.325649 | 0.102498 | 0.328519 | 0.102573 |
| 45 | 133 | 4.943590e-08 | 0.103334 | 0.326803 | 0.103473 | 0.321474 | 0.103362 |
| 46 | 96 | 5.013611e-08 | 0.102532 | 0.325522 | 0.102558 | 0.328560 | 0.102537 |
| 47 | 148 | -5.638632e-08 | 0.102877 | 0.326021 | 0.102527 | 0.325705 | 0.102807 |
| 48 | 95 | -4.618958e-08 | 0.102155 | 0.325058 | 0.102273 | 0.332594 | 0.102179 |
| 49 | 131 | 4.888754e-08 | 0.102431 | 0.325105 | 0.102663 | 0.329156 | 0.102477 |
So as expected, Train_diff is now zero - the predicted mean for all our models is exactly the same as the training data mean, because we set it that way.
But do we lose any predictive power from this?
fixed_bias_val_loss = pd.DataFrame(results).Val_loss.mean()
print(fixed_bias_val_loss, avg_val_loss, fixed_bias_val_loss - avg_val_loss)
0.32818478763103487 0.32853454232215884 -0.0003497546911239713
Let us also look at some diagnostics:
# Load the best model in the last run
model.load_state_dict(torch.load('best_model.pt'))
y_val_pred = model(x_val_numerical, x_val_categorical)
val_data["predicted"] = y_val_pred.cpu().detach().numpy().ravel() * val_data.expo
val_data["trueclaims"] = val_data.truefreq * val_data.expo
fig, axs = plt.subplots(len(numerical_feats) + 1, sharex=False, sharey=True, figsize=(7, 40))
for i, f in enumerate(["predicted"] + numerical_feats):
dat_copy = val_data.copy()
dat_copy["decile"] = pd.qcut(dat_copy[f], 10, labels=False, duplicates='drop')
X_sum = dat_copy.groupby("decile").agg("sum").reset_index()
axs[i].plot(X_sum.index, X_sum.trueclaims / X_sum.expo)
axs[i].plot(X_sum.index, X_sum.predicted / X_sum.expo)
axs[i].set_title(f)
for i, f in enumerate(categorical_feats):
dat_copy = val_data.copy()
X_sum = dat_copy.groupby(f).agg("sum")[["trueclaims", "predicted", "expo"]]
X_sum["trueclaims"] = X_sum["trueclaims"]/X_sum["expo"]
X_sum["predicted"] = X_sum["predicted"]/X_sum["expo"]
X_sum = X_sum.drop(columns="expo")
axs[i] = X_sum.plot(kind='bar', rot=0, xlabel=f, ylabel='Value', title=f)

Conclusions#
ChatGPT is an effective tool for accelerating actuarial data science programming. However, users need to have sufficient understanding to debug the resulting generated code, and identify any subtle logic errors, additional requirements, or best practices.
Early stopping does lead to models that are biased. The bias itself is not biased, it averages around the mean, but any given model may be biased.
We propose other ideas to avoid this other than the solution proposed by Wuthrich.
Ensemble a group of models, which will average out biases.
Increase the learning rate on the bias to ensure that remains close to the right levels. Note that our initialisation strategy means the bias already starts at the right level.
Reset the bias so the mean reconciles after each epoch
Appendix: Unedited ChatGPT code output#
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import mean_squared_error
# Define the neural network class
class FeedForwardNet(nn.Module):
def __init__(self, num_numerical_feats, num_categorical_feats, embedding_sizes, hidden_size):
super(FeedForwardNet, self).__init__()
self.embeddings = nn.ModuleList([
nn.Embedding(num_classes, emb_size) for num_classes, emb_size in embedding_sizes
])
self.num_numerical_feats = num_numerical_feats
self.num_categorical_feats = num_categorical_feats
self.total_embed_size = sum([emb_size for _, emb_size in embedding_sizes])
self.input_size = self.num_numerical_feats + self.total_embed_size
self.fc1 = nn.Linear(self.input_size, hidden_size)
self.fc2 = nn.Linear(hidden_size, 1)
self.dropout = nn.Dropout(p=0.2)
def forward(self, x_numerical, x_categorical):
embedded_x = [embedding(x_categorical[:, i]) for i, embedding in enumerate(self.embeddings)]
embedded_x = torch.cat(embedded_x, dim=1)
x = torch.cat([embedded_x, x_numerical], dim=1)
x = self.dropout(x)
x = torch.relu(self.fc1(x))
x = self.dropout(x)
x = self.fc2(x)
return x
# Load the dataset
data = pd.read_csv('your_dataset.csv')
# Split the dataset into training and validation sets
train_data, val_data = train_test_split(data, test_size=0.2, random_state=42)
# Define the categorical features and numerical features
categorical_feats = ['gas', 'brand', 'area', 'ct']
numerical_feats = ['age', 'ac', 'power', 'dens']
# Encode the categorical features using LabelEncoder
label_encoders = {}
for feat in categorical_feats:
label_encoders[feat] = LabelEncoder()
train_data[feat] = label_encoders[feat].fit_transform(train_data[feat])
val_data[feat] = label_encoders[feat].transform(val_data[feat])
# Define the embedding sizes for categorical features
embedding_sizes = [(len(train_data[feat].unique()), min(50, (len(train_data[feat].unique()) + 1) // 2)) for feat in categorical_feats]
# Convert the dataset to PyTorch tensors
x_train_numerical = torch.tensor(train_data[numerical_feats].values, dtype=torch.float32)
x_train_categorical = torch.tensor(train_data[categorical_feats].values, dtype=torch.long)
y_train = torch.tensor(train_data['claims'].values, dtype=torch.float32)
exposure_train = torch.tensor(train_data['expo'].values, dtype=torch.float32)
x_val_numerical = torch.tensor(val_data[numerical_feats].values, dtype=torch.float32)
x_val_categorical = torch.tensor(val_data[categorical_feats].values, dtype=torch.long)
y_val = torch.tensor(val_data['claims'].values, dtype=torch.float32)
exposure_val = torch.tensor(val_data['expo'].values, dtype=torch.float32)
# Define the hyperparameters
hidden_size = 64
learning_rate = 0.001
batch_size = 32
num_epochs = 100
early_stopping_epochs = 10
# Create an instance of the FeedForwardNet model
model = FeedForwardNet(len(numerical_feats), len(categorical_feats), embedding_sizes, hidden_size)
# Define the loss function
criterion = nn.MSELoss(reduction='sum')
# Define the optimizer
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
# Train the model
best_val_loss = np.inf
best_epoch = 0
for epoch in range(num_epochs):
model.train()
optimizer.zero_grad()
y_pred = model(x_train_numerical, x_train_categorical)
loss = criterion(y_pred.squeeze() * exposure_train, y_train * exposure_train)
loss.backward()
optimizer.step()
model.eval()
with torch.no_grad():
y_val_pred = model(x_val_numerical, x_val_categorical)
val_loss = criterion(y_val_pred.squeeze() * exposure_val, y_val * exposure_val)
if val_loss < best_val_loss:
best_val_loss = val_loss
best_epoch = epoch
torch.save(model.state_dict(), 'best_model.pt')
if epoch - best_epoch >= early_stopping_epochs:
break
# Load the best model
model.load_state_dict(torch.load('best_model.pt'))
# Make predictions on the test set
x_test_numerical = torch.tensor(test_data[numerical_feats].values, dtype=torch.float32)
x_test_categorical = torch.tensor(test_data[categorical_feats].values, dtype=torch.long)
y_test = torch.tensor(test_data['claims'].values, dtype=torch.float32)
exposure_test = torch.tensor(test_data['expo'].values, dtype=torch.float32)
model.eval()
with torch.no_grad():
y_test_pred = model(x_test_numerical, x_test_categorical)
# Calculate the test loss
test_loss = criterion(y_test_pred.squeeze() * exposure_test, y_test * exposure_test)
test_rmse = torch.sqrt(test_loss.item() / len(test_data))
print(f'Test RMSE: {test_rmse:.4f}')