R: Bayesian Applications#
By Pat Reen - originally published on his GitHub site here, which has the original code.
Background#
Bayesian statistics reflects uncertainty about model parameters by assuming some prior probability distribution for those parameters. That prior uncertainty is adjusted for observed data to produce a posterior distribution.
Under a frequentest approach, model parameters are fixed and the observations are assumed to be sampled from a probability distribution with those parameters.
\(\Huge {p}(\theta,x) = \frac{{p}(x,\theta){p}(\theta)}{{p}(x)}\)
Where
\({p}(\theta,x)\) is the posterior, a combination of the likelihood, prior and evidence. Probability distribution of \(\theta\) given the observed data, \(x\).
\({p}(x,\theta)\) is the likelihood which summarizes the likelihood of observing data \(x\) under different values of the underlying support parameter \(\theta\).
\({p}(\theta)\) is the prior, the probability distribution of \(\theta\), independent of the observed data.
\({p}(x)\) is the evidence (normalising term), the probability of the observed data \(x\), independent of \(\theta\).
The evidence term is proportional to the likelihood and therefore the theorem is often stated as
\(\Huge p(\theta | x) \propto p(x | \theta) p(\theta)\)
A paper presented at the 2021 Actuaries (Institute) Summit (p2) sets out the ‘tensions’ that exist between Frequentest and Bayesian approaches and suggests that:
“Despite actuaries being pioneers in early work on credibility theory, Bayesian approaches have largely given way to frequentist approaches. This is to our loss, since such methods have advanced substantially over the past couple of decades and they are well-suited to problems with latent variables or noise around underlying ‘true’ values.”
Here we’ll look at a few simple applications of Bayesian techniques.
Applications#
The sections below set out a simple example Bayesian refresher, regression models and other applications.
Libraries#
A list of packages used in the recipes.
library(base) # Base r functions
library(fitdistrplus) # Fit of univariate distributions to non-censored data
library(lubridate) # tidyverse: dealing with dates
library(ggplot2) # tidyverse: graphs
library(gridExtra) # tidyverse: arranging graphs
library(ggthemes) # tidyverse: additional themes for ggplot, optional
library(dplyr) # tidyverse: data manipulation
library(tidyr) # tidyverse: tidy messy data
library(broom) # tidyverse: visualising statistical objects
library(DataExplorer) # package for exploratory data analysis
library(scales) # data formatting
library(stats) # statistical functions
library(rstan) # interface for stan platform
library(bayesplot) # Plotting bayesian models (ggplot extension)
library(rjags) # alternative interface for stan platform, regression applications
# library(EpiNow2) # epidemiological model with stan backend; not called here as we'll use a pre-run model
# library(rstanarm) # interface for stan platform, regression applications; not called here
Loading required package: MASS
Loading required package: survival
Attaching package: 'lubridate'
The following objects are masked from 'package:base':
date, intersect, setdiff, union
Attaching package: 'dplyr'
The following object is masked from 'package:gridExtra':
combine
The following object is masked from 'package:MASS':
select
The following objects are masked from 'package:stats':
filter, lag
The following objects are masked from 'package:base':
intersect, setdiff, setequal, union
Loading required package: StanHeaders
rstan (Version 2.21.2, GitRev: 2e1f913d3ca3)
For execution on a local, multicore CPU with excess RAM we recommend calling
options(mc.cores = parallel::detectCores()).
To avoid recompilation of unchanged Stan programs, we recommend calling
rstan_options(auto_write = TRUE)
Do not specify '-march=native' in 'LOCAL_CPPFLAGS' or a Makevars file
Attaching package: 'rstan'
The following object is masked from 'package:tidyr':
extract
This is bayesplot version 1.8.0
- Online documentation and vignettes at mc-stan.org/bayesplot
- bayesplot theme set to bayesplot::theme_default()
* Does _not_ affect other ggplot2 plots
* See ?bayesplot_theme_set for details on theme setting
Warning message:
"package 'rjags' was built under R version 4.0.5"
Loading required package: coda
Attaching package: 'coda'
The following object is masked from 'package:rstan':
traceplot
Linked to JAGS 4.2.0
Loaded modules: basemod,bugs
Mental health example#
The 2017 Actuaries Institute Green Paper on Mental Health and Insurance talks about some of the challenges in obtaining reliable data and projections on mental health in insurance (p26):
“There are sources of data and research about the prevalence and profile of people with different mental health conditions, such as the 2007 National Survey of Mental Health and Wellbeing and many other epidemiological and clinical studies… [T]o have a complete and informed view of all this information is a difficult task for a full-time academic, let alone for an insurer.
Even then, the nature and granularity of the data needed for insurance applications is different from that for population, public health or clinical purposes. Firstly, the ‘exposure’ (the number of insured people and their characteristics) needs to be recorded. There is probably a lot of relevant information that is not collected at the start of an insurance policy and can therefore never be analysed.
Secondly, the claims information needs to be available at a detailed level regarding the nature and cause of the claim and other characteristics of the individual, their history and the cover provided. There is a clear need for consistency in definition, language and data standards to improve the quality of information available across the system.
Naturally, when the insurance cover for mental health conditions is not provided (as in the case of most travel insurance products) there will not be relevant data from the insurance history. However, even when relevant data exists within insurers there are practical and commercial difficulties in turning it into a useful form.”
The paper goes on to talk about some of the insurance challenges in detail including
subjectivity in diagnosis
reliance on self-reporting
varying severity and prospects of recovery
impact of co-morbidities
correlation with financial incentive
Based upon data from a single insurer ~19% of IP and TPD claims relate to mental health, with mental health claims contributing 26% to the total cost of claims (in 2015, p17). This is roughly consistent with the proportion of the general population that experiences an episode of mental illness in a 12 month period, from the Productivity Commission, p110.
In this simple example, we want to know what the rate of mental illness, \(\theta\) is in the insured population. Assume some true underlying \(\theta\), here a fixed value of 20%. Create a population, \(X\) with \(X \sim B(N,\theta)\) where N=100000. Pull a random sample from population.
theta_true <- 0.2
pop <- rbinom(100000,1,theta_true)
sample_n = 500
sample <- sample(pop,sample_n)
sample_success <- sum(sample)
sample_p <- sample_success/sample_n
Choosing a prior#
The posterior is proportional to the product of the prior and the likelihood. The beta distribution is a conjugate prior for the binomial distribution (posterior is the same probability distribution family as prior). Assume \(\theta \sim {\sf Beta}(\alpha, \beta)\), then:
\(f(\theta;\alpha,\beta) = \theta^{\alpha-1}(1-\theta)^{\beta-1}\)
It represents the probabilities assigned to values of \(\theta\) in the domain (0,1) given values for the parameters \(\alpha\) and \(\beta\). The binomial posterior distribution represents the probability of values of \(X\) given \(\theta\). Varying the values of \(\alpha\) and \(\beta\) can represent a wide range of different prior beliefs about the distribution of \(\theta\).
Priors can be “informative” “uninformative” or “weakly informative”, e.g.
non-informative - uniform dist => \(\theta\) could be anywhere in (0,1)
weakly informative uniform prior => believe \(\theta\) more likely to be at either end of the ranges (less likely to be in the middle)
strongly informative prior
a and b both high (bimodial) => true theta likely to be at center of range
a higher than b (strong “success”) => success more likely than failure (where “success” is a mental health claim)
b higher than a (strong “failure”) => failure more likely than success
Defining prior plots:
plot_prior <- function(a,b){
theta = seq(0,1,0.005)
p_theta = dbeta(theta, a, b)
p <- qplot(theta, p_theta, geom='line')
p <- p + theme_bw()
p <- p + ylab(expression(paste('p(',theta,')', sep = '')))
p <- p + xlab(expression(theta))
return(p)}
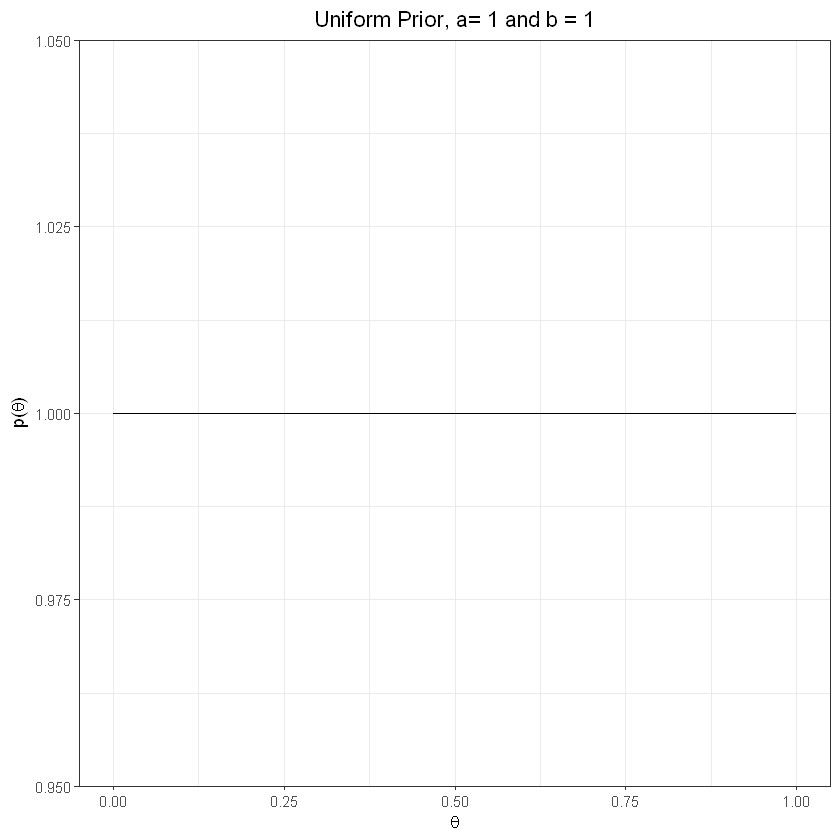
Non-informative prior, uniform#
plot_prior(1,1) + labs(title="Uniform Prior, a= 1 and b = 1") + theme(plot.title = element_text(hjust = 0.5))
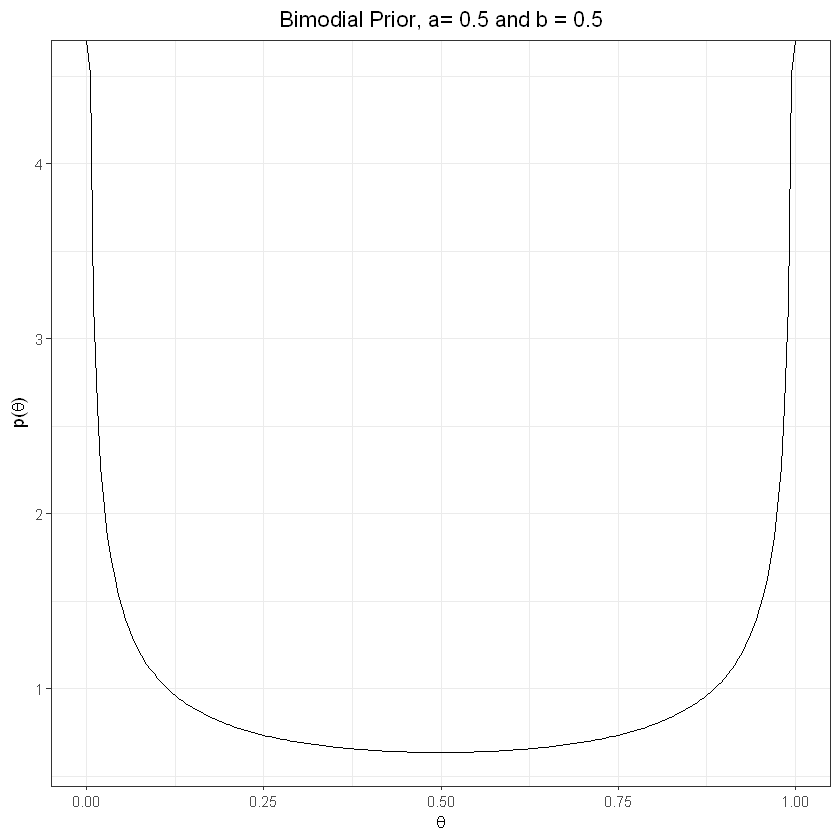
Weakly informative prior, bimodial#
plot_prior(0.5,0.5) + labs(title="Bimodial Prior, a= 0.5 and b = 0.5") + theme(plot.title = element_text(hjust = 0.5))
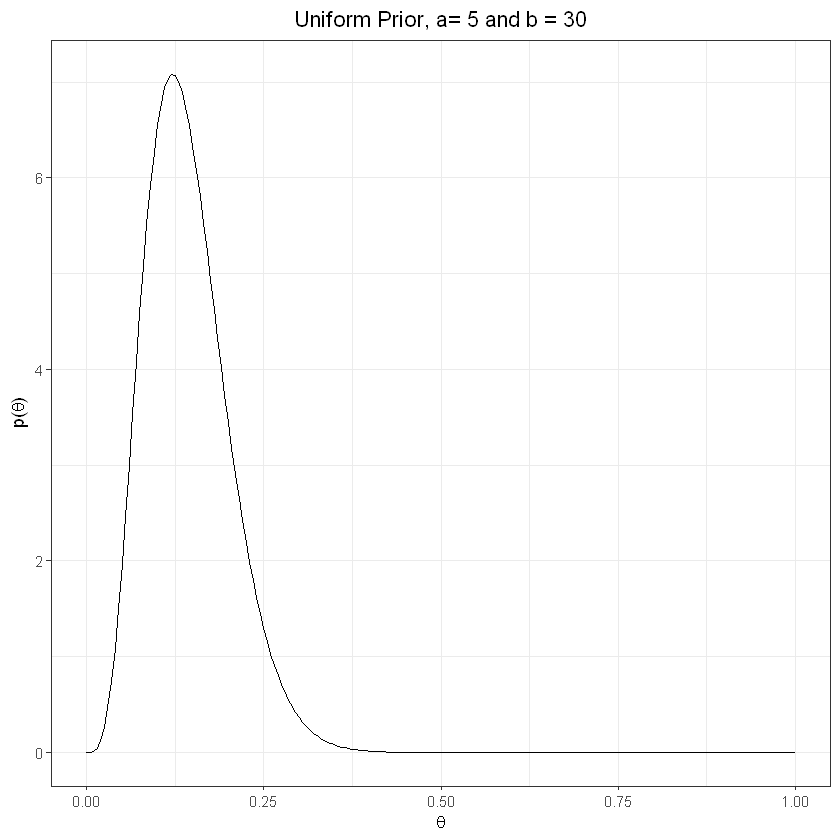
Informative prior, “failure” more likely#
The higher the number of observations, the greater the influence on the posterior
plot_prior(5,30) + labs(title="Uniform Prior, a= 5 and b = 30") + theme(plot.title = element_text(hjust = 0.5))
plot_prior(20,120) + labs(title="Uniform Prior, a= 20 and b = 120") + theme(plot.title = element_text(hjust = 0.5))
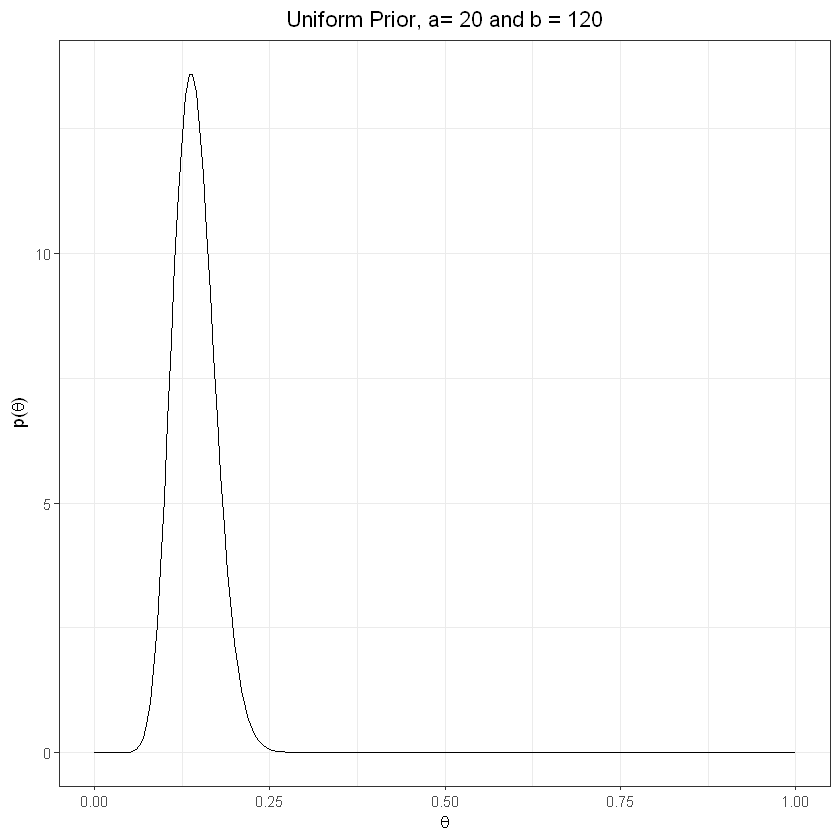
Deriving posterior#
Prior plot values. Re-express binomial as beta dist.
prior_a = 50 #successes
prior_b = 250 #failures
prior_n = prior_a + prior_b #observations
prior_theta = prior_a/prior_n
prior <- data.frame('Dist'='Prior','x'=seq(0,1,0.005), 'y'=dbeta(seq(0,1,0.005),prior_a,prior_b))
Observations are taken from the earlier binomial sample.
obs_a <- sample_success + 1
obs_b <- sample_n - sample_success + 1
observations <- data.frame('Dist'='Observations',x=seq(0,1,0.005), y=dbeta(seq(0,1,0.005),obs_a,obs_b))
In this example, the posterior is a simple combination of the prior and observations.
post_a <- sample_success + prior_a - 1 #combination of prior and observed successes
post_b <- sample_n - sample_success + prior_b - 1
post_theta <- post_a / (post_a + post_b)
posterior <- data.frame('Dist'='Posterior','x'=seq(0,1,0.005), 'y'=dbeta(seq(0,1,0.005),post_a,post_b))
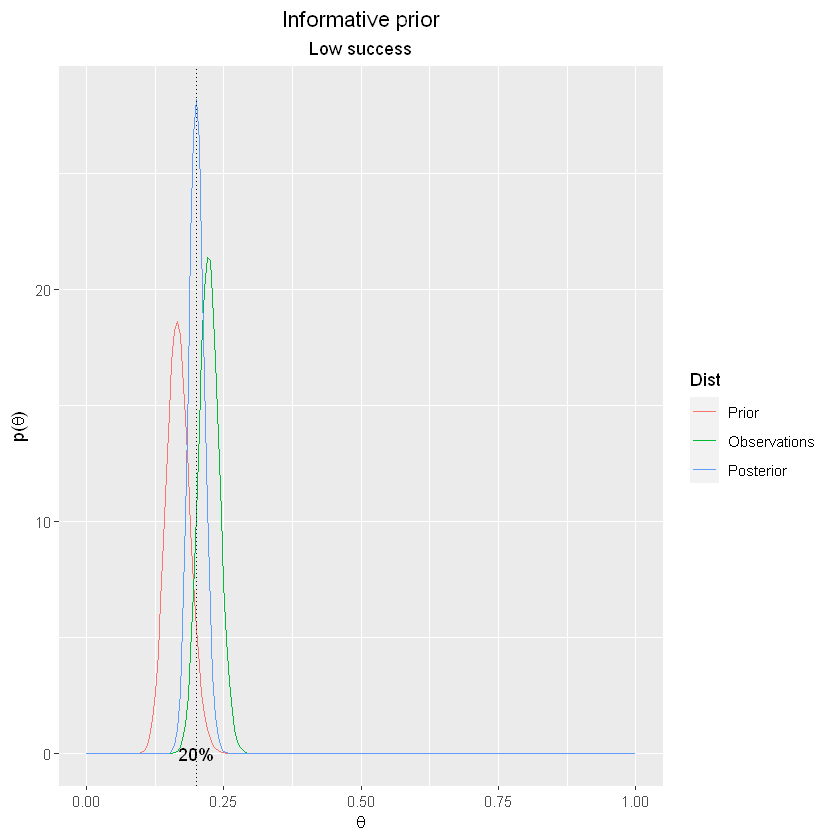
This can be plotted as:
model_plot <- rbind(prior,observations,posterior)
with(model_plot, Dist <- factor(Dist, levels = c('Prior', 'Observations','Posterior'), ordered = TRUE))
qplot(model_plot$x, model_plot$y, geom='line',color = model_plot$Dist) +
ylab(expression(paste('p(',theta,')', sep = ''))) +
xlab(expression(theta)) +
geom_vline(xintercept = post_theta, linetype="dotted", color = "black", label="blah") +
scale_color_discrete(name = "Dist") +
annotate("text",x=post_theta, y=0, label=label_percent()(post_theta)) +
labs(title="Informative prior", subtitle="Low success") +
theme(plot.title = element_text(hjust = 0.5)) +
theme(plot.subtitle = element_text(hjust = 0.5))
Warning message:
"Ignoring unknown parameters: label"
Regression - logistic#
Background#
RSTANARM is an interface in R for STAN where Stan is a platform for Bayesian inference - it is a probabilistic programming framework where the guts of the inference method happens in the background, while the user focuses on parameterising the model in R. RJAGS is an interface in R for JAGS (Just Another Gibbs Sample) where JAGS is similarly a platform for Bayesian modeling.
Models in both STAN and JAGS can make use of Markov chains Monte Carlo (MCMC) methods. MCMC methods provide a way to take random samples approximately from a posterior distribution. Such samples can be used to summarize any aspect of the posterior distribution of a statistical model.
RSTANARM and RJAGS have pre-written code for common models like regression.
Under a Frequentest approach to linear regression, for a given set of response variables y, the relationship between y and a set of regressor variables x is assumed to be linear (informed by a set of parameters \(\beta\)), with an error term, i.e. \(y = X\beta + \epsilon\).
The error term, \(\epsilon\) is assumed to be normally distributed and the regression co-efficients are estimated by minimising the error term commonly using ordinary least squares (OLS). We make some other assumptions about the error term - not correlated with X and i.i.d.; and define \(Var(\epsilon)=\sigma^2\). The generalised form allows the response variable to have an error that is not normal - this is achieved by allowing the linear model to be related to the response variable via a link function and by allowing the magnitude of the variance of each measurement to be a function of its predicted value.
With Bayesian inference we are interested in the posterior distributions of the parameters \(\beta\) and \(\sigma\), rather than point estimates. We also want to influence those distributions with some prior knowledge of their behaviour:
\(p(\beta,\sigma|y,X) \propto p(y|\beta,\sigma)p(\beta,\sigma)\)
\(p(\beta,\sigma|y,X)\) is not a normalised probability density function (i.e. is proportional to the likelihood and prior). However, we can sample from it and therefore estimate any quantity of interest e.g. mean or variance, Numerical Recipes, p825. For this we use MCMC:
“MCMC is a random sampling method… the goal is to visit a point \(x\) with a probability proportional to some given distribution function \(\pi(x)\) [not necessarily a probability]. Why would we want to sample a distribution in this way? THe answer is that Bayesian methods, often implemented using MCMC, provide a powerful way of estimating the parameters of a model and their degree of uncertainty.”
Heart disease data#
The Framingham Heart Study is a longitudinal study of cardiovastular disease in a sample population within Framingham, Massachusetts. A subset of data for teaching is available at request from the U.S. National Heart, Lung and Blood Institute. This dataset is not appropriate for publication and has been anonymised, but is nevertheless useful for illustrative purposes here. The dataset:
“..is a subset of the data collected as part of the Framingham study and includes laboratory, clinic, questionnaire, and adjudicated event data on 4,434 participants. Participant clinic data was collected during three examination periods, approximately 6 years apart, from roughly 1956 to 1968. Each participant was followed for a total of 24 years for the outcome of the following events: Angina Pectoris, Myocardial Infarction, Atherothrombotic Infarction or Cerebral Hemorrhage (Stroke) or death.”
We’ll look at a logistic regression model example using predefined Bayesian models in RSTANARM.
df_heart <- read.csv(file = '../_static/bayesian_applications/frmgham2.csv')
df_heart <- df_heart[c(1:23)] %>% filter(PERIOD==2) # ignoring health event data, only looking at observations at period == 2 (observations for participants are not independent over time; this does have limitations e.g. observations are truncated at death which could be due to heart disease)
ignore_cols <- names(df_heart) %in% c("PERIOD","RANDID","TIME", "PREVMI", "PREVAP") #exclude identifier and time columns; exclude PREVMI and PREVAP as they are a subset of PREVCHD
df_heart <- df_heart[!ignore_cols]
head(df_heart)
| SEX | TOTCHOL | AGE | SYSBP | DIABP | CURSMOKE | CIGPDAY | BMI | DIABETES | BPMEDS | HEARTRTE | GLUCOSE | educ | PREVCHD | PREVSTRK | PREVHYP | HDLC | LDLC |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 | 260 | 52 | 105 | 69.5 | 0 | 0 | 29.43 | 0 | 0 | 80 | 86 | 2 | 0 | 0 | 0 | NA | NA |
| 1 | 283 | 54 | 141 | 89.0 | 1 | 30 | 25.34 | 0 | 0 | 75 | 87 | 1 | 0 | 0 | 0 | NA | NA |
| 2 | 232 | 67 | 183 | 109.0 | 1 | 20 | 30.18 | 0 | 0 | 60 | 89 | 3 | 0 | 0 | 1 | NA | NA |
| 2 | 343 | 51 | 109 | 77.0 | 1 | 30 | 23.48 | 0 | 0 | 90 | 72 | 3 | 0 | 0 | 0 | NA | NA |
| 2 | 230 | 49 | 177 | 102.0 | 0 | 0 | 31.36 | 0 | 1 | 120 | 86 | 2 | 0 | 0 | 1 | NA | NA |
| 2 | 220 | 70 | 149 | 81.0 | 0 | 0 | 36.76 | 0 | 0 | 80 | 98 | 1 | 1 | 0 | 1 | NA | NA |
Data description (available at the NHLBI at the link above) highlights:
RANDIND: unique identifier.
SEX: 1=male; 2=female (categorical, 1/2).
TIME: number of days since baseline exam (continuous).
PERIOD: examination cycle (categorical, 1,2 or 3). We’ll focus on period 2 - observations for the same participant are not independent over time.
TOTCHOL: total cholesterol level (continuous).
AGE: Age of the patient rounded to nearest year (continuous).
SYSBP: systolic blood pressure (continuous).
DIABP: diastolic blood pressure (continuous).
CURSMOKE: whether or not the patient is a current smoker (categorical, 0/1).
CIGPDAY: the number of cigarettes smoked per day on average (continuous).
BMI: Body Mass Index (continuous).
DIABETES: whether or not the patient had diabetes (categorical, 0/1).
BPMEDS: whether or not the patient was on blood pressure medication (categorical, 0/1).
HEARTRTE: heart rate (continuous).
GLUCOSE: glucose level (continuous).
EDU: attained Education (categorical, 1=0-11 year; 2=High School Diploma, GED; 3=Some College, Vocational School; 4=College (BS, BA) degree or more).
HDLC: High Density Lipoprotein Cholesterol - only available for period 3 (continuous).
LDLC: Low Density Lipoprotein Cholesterol - only available for period 3 (continuous).
PREVCHD: prevalence of Coronary Heart Disease (categorical, 0/1).
PREVAP: prevalence of Angina Pectoris (categorical, 0/1). Excluded from model as it is a subset of PREVCHD.
PREVMI: Prevalence of Myocardial Infarction (categorical, 0/1). Excluded from model as it is a subset of PREVCHD.
PREVSTRK: whether or not the patient had previously had a stroke (categorical, 0/1).
PREVHYP: whether or not the patient was hypertensive (categorical, 0/1).
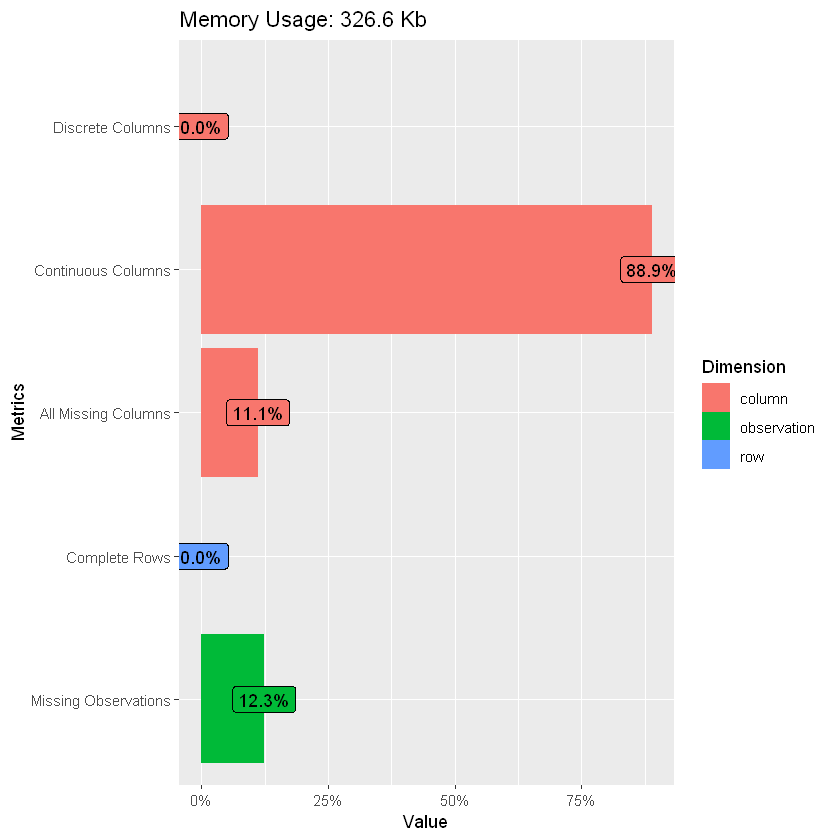
Using the DataExplore package, we can see that the data is mostly complete apart from missing entries in ‘glucose’ and to a lesser extent ‘education’.
introduce(df_heart)
plot_intro(df_heart)
plot_missing(df_heart)
| rows | columns | discrete_columns | continuous_columns | all_missing_columns | total_missing_values | complete_rows | total_observations | memory_usage |
|---|---|---|---|---|---|---|---|---|
| 3930 | 18 | 0 | 16 | 2 | 8720 | 0 | 70740 | 334464 |
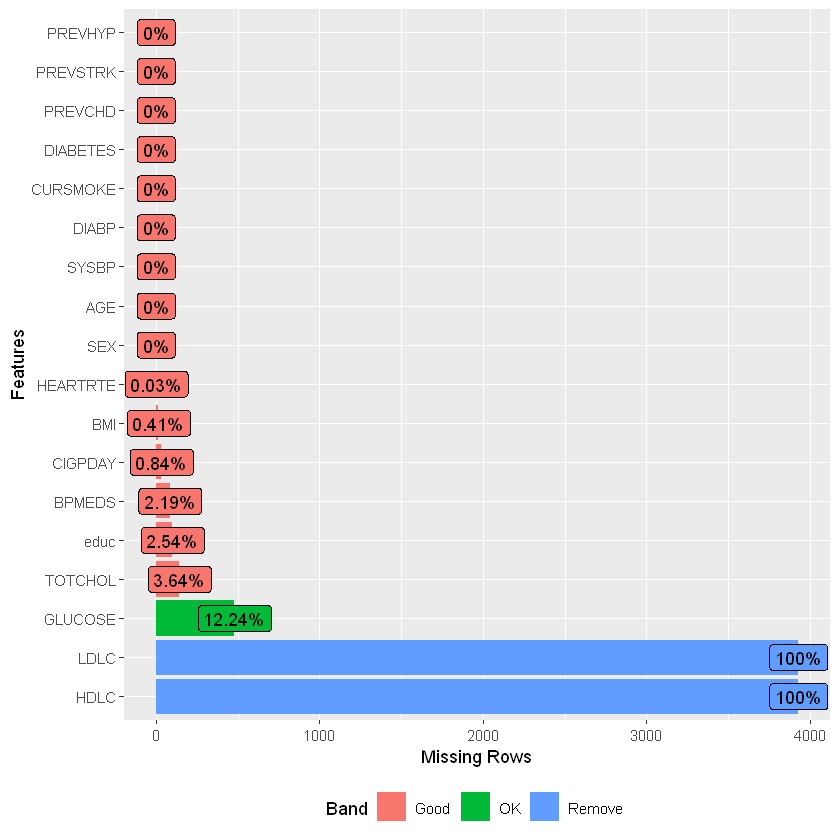
Given around 12% of glucose records are missing as well as all of HDL and LDL (only available for period 3), drop the columns. Also drop rows with other missing data as these are small in number.
df_heart$GLUCOSE <- NULL
df_heart$HDLC <- NULL
df_heart$LDLC <- NULL
df_heart <- na.omit(df_heart)
Plots of the data:
plot_bar(df_heart, title="Barplot")
Of the 3.6k remaining records, ~7% have a flag for heart disease:
table(df_heart$PREVCHD)
0 1
3319 253
Further plots and checking distributions:
plot_histogram(df_heart, title="Histogram for continuous")
qq_data <- df_heart[,c("BMI", "DIABP", "HEARTRTE", "SYSBP", "TOTCHOL")]
plot_qq(qq_data, title="QQ plot")
log_qq_data <- update_columns(qq_data, 2:4, function(x) log(x + 1))
plot_qq(log_qq_data, title="QQ plot, logged data")
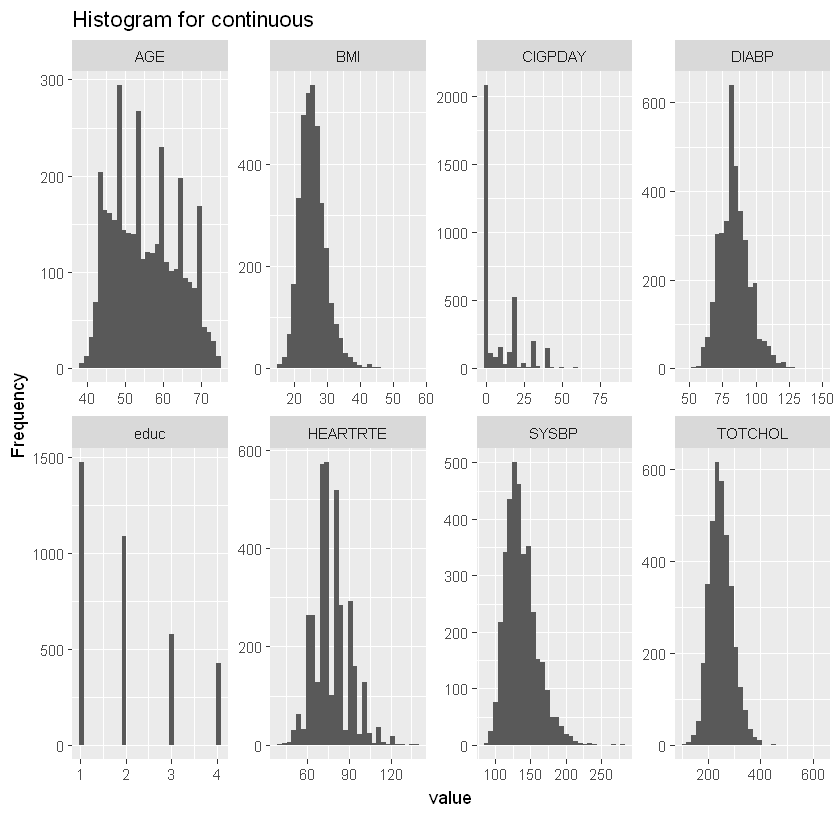
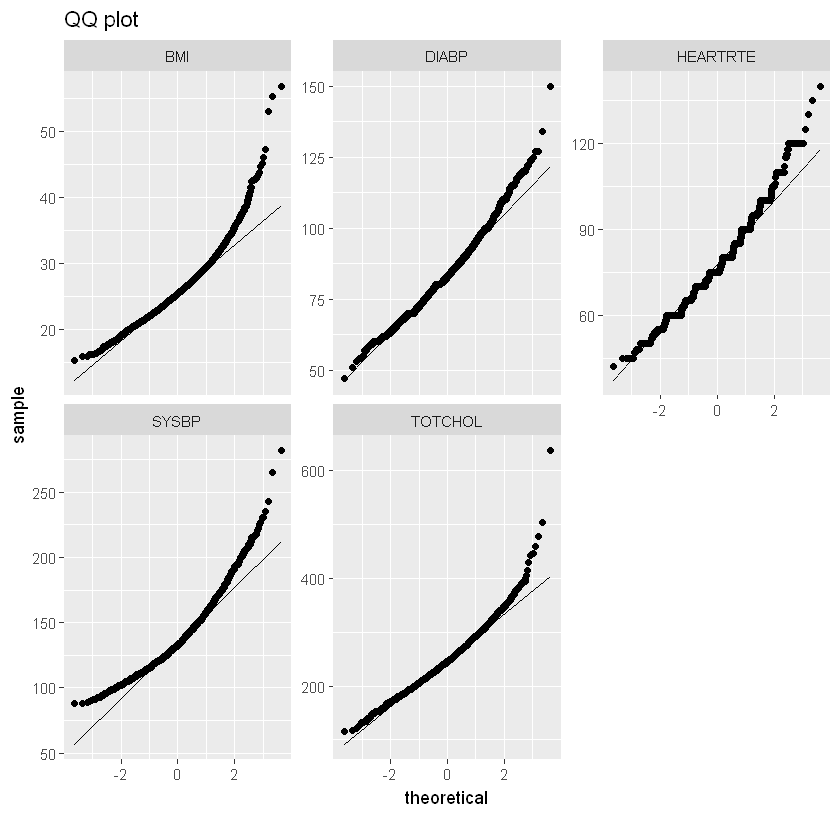
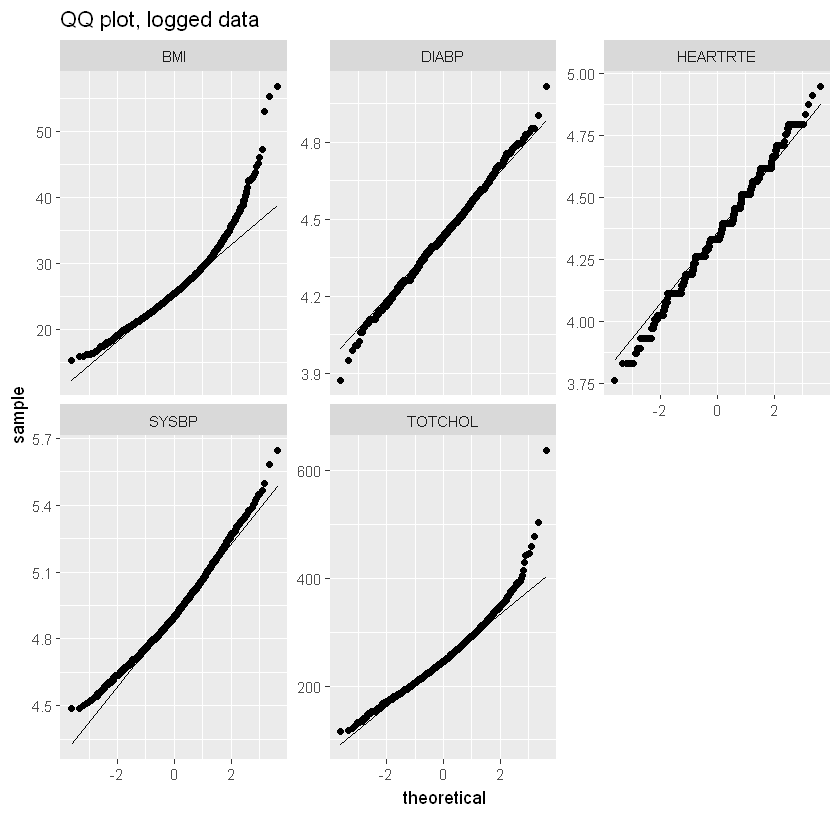
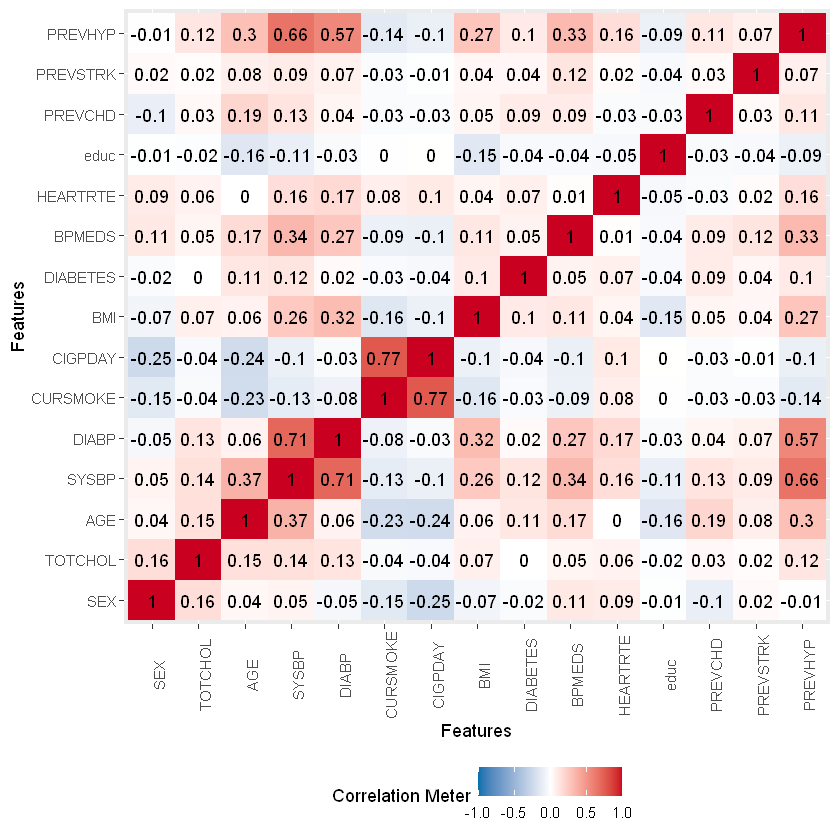
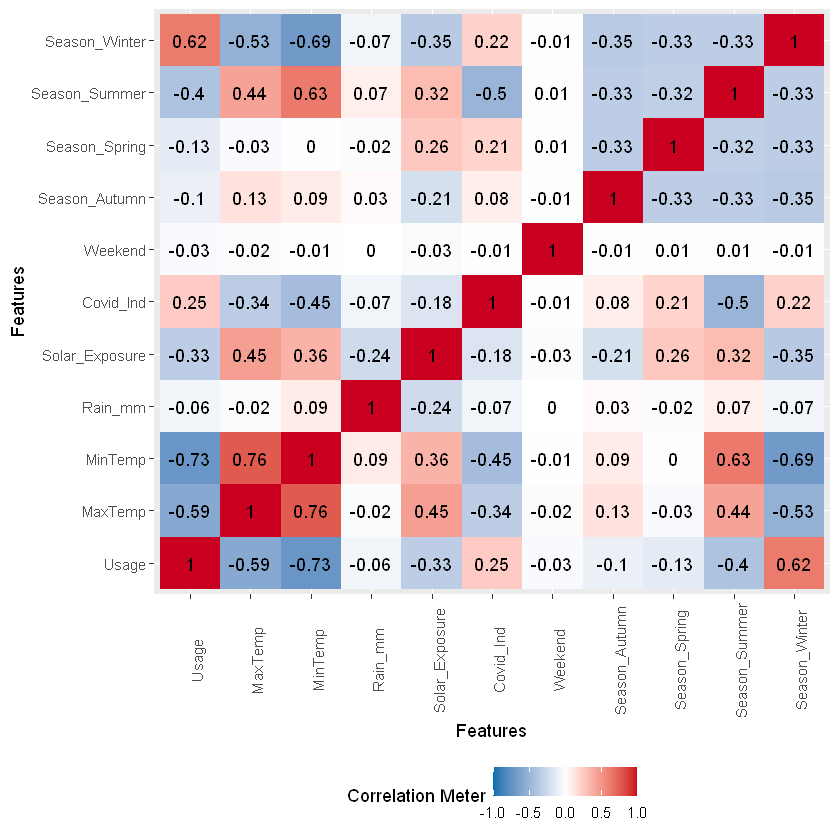
Most significantly correlated with heart disease are AGE, SYSBP, DIABETES, BPMEDS and PREVHYP.
plot_correlation(na.omit(df_heart))
Split data into training and testing data sets.
# Create a random sample of row IDs
sample_rows <- sample(nrow(df_heart),0.75*nrow(df_heart))
# Create the training dataset
df_heart_train <- df_heart[sample_rows,]
# Create the test dataset
df_heart_test <- df_heart[-sample_rows,]
Fit a simple GLM using all data:
full_model_glm <- glm(PREVCHD~.,data=df_heart_train, family = "binomial")
summary(full_model_glm)
Call:
glm(formula = PREVCHD ~ ., family = "binomial", data = df_heart_train)
Deviance Residuals:
Min 1Q Median 3Q Max
-1.3274 -0.4061 -0.2666 -0.1721 3.0678
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -7.771752 1.252690 -6.204 5.50e-10 ***
SEX -1.163457 0.179755 -6.472 9.64e-11 ***
TOTCHOL 0.002251 0.001766 1.274 0.20250
AGE 0.086854 0.011635 7.465 8.34e-14 ***
SYSBP 0.010511 0.005092 2.064 0.03900 *
DIABP -0.014227 0.009529 -1.493 0.13544
CURSMOKE 0.340968 0.255911 1.332 0.18274
CIGPDAY -0.006939 0.010363 -0.670 0.50315
BMI 0.053302 0.020091 2.653 0.00798 **
DIABETES 0.392274 0.291334 1.346 0.17815
BPMEDS 0.531433 0.222946 2.384 0.01714 *
HEARTRTE -0.013636 0.006523 -2.090 0.03659 *
educ 0.099809 0.076119 1.311 0.18978
PREVSTRK 0.218284 0.490566 0.445 0.65635
PREVHYP 0.374206 0.221446 1.690 0.09106 .
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 1366.6 on 2678 degrees of freedom
Residual deviance: 1174.0 on 2664 degrees of freedom
AIC: 1204
Number of Fisher Scoring iterations: 6
Use stepwise regression to reduce the explanatory variables:
# specify a null model with no predictors
null_model_glm <- glm(PREVCHD ~ 1, data = df_heart_train, family = "binomial")
# use a forward stepwise algorithm to build a parsimonious model
step_model_glm <- step(null_model_glm, scope = list(lower = null_model_glm, upper = full_model_glm), direction = "forward")
Summary of the model:
summary(step_model_glm)
Call:
glm(formula = PREVCHD ~ AGE + SEX + SYSBP + BPMEDS + BMI + HEARTRTE +
PREVHYP + DIABP, family = "binomial", data = df_heart_train)
Deviance Residuals:
Min 1Q Median 3Q Max
-1.2381 -0.4063 -0.2700 -0.1729 3.0992
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -6.776549 1.106023 -6.127 8.96e-10 ***
AGE 0.084172 0.011073 7.601 2.93e-14 ***
SEX -1.134134 0.170509 -6.651 2.90e-11 ***
SYSBP 0.011127 0.005026 2.214 0.0268 *
BPMEDS 0.538117 0.218937 2.458 0.0140 *
BMI 0.047248 0.019361 2.440 0.0147 *
HEARTRTE -0.012867 0.006413 -2.006 0.0448 *
PREVHYP 0.367789 0.220910 1.665 0.0959 .
DIABP -0.014075 0.009425 -1.493 0.1353
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 1366.6 on 2678 degrees of freedom
Residual deviance: 1181.3 on 2670 degrees of freedom
AIC: 1199.3
Number of Fisher Scoring iterations: 6
Dropping BPMEDS, HEARTRTE and BMI as little impact on AIC:
final_model_glm <- glm(PREVCHD ~ AGE + SEX + PREVHYP + DIABETES + TOTCHOL, family = "binomial",data = df_heart_train)
summary(final_model_glm)
Call:
glm(formula = PREVCHD ~ AGE + SEX + PREVHYP + DIABETES + TOTCHOL,
family = "binomial", data = df_heart_train)
Deviance Residuals:
Min 1Q Median 3Q Max
-1.1702 -0.4182 -0.2772 -0.1830 3.0145
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -7.371509 0.734203 -10.040 < 2e-16 ***
AGE 0.091994 0.010190 9.028 < 2e-16 ***
SEX -1.084013 0.168352 -6.439 1.2e-10 ***
PREVHYP 0.622003 0.176473 3.525 0.000424 ***
DIABETES 0.543020 0.282690 1.921 0.054744 .
TOTCHOL 0.002377 0.001755 1.354 0.175643
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 1366.6 on 2678 degrees of freedom
Residual deviance: 1198.5 on 2673 degrees of freedom
AIC: 1210.5
Number of Fisher Scoring iterations: 6
Fit a Bayes glm using the same explanatory variables. Here parameter estimates no longer have test statistics and p-values as in the frequentist regression. This is because Bayesian estimation samples from the posterior distribution. This means that instead of a point estimate and a test statistic, we get a distribution of plausible values for the parameters, and the estimates section of the summary summarizes those distributions.
Further documentation on Bayesian generalised linear models via Stan is here. Documentation on choice of priors is here. If priors are not specified, default weekly informative priors are used - you can call a summary of the modeled priors (see below). Default priors are autoscaled to make them less informative (see below for notes on scaling).
not_run_sample_only <- function(){model_bayes_glm_heart <- stan_glm(PREVCHD ~ AGE + SEX + PREVHYP + DIABETES + TOTCHOL, family = "binomial",data=df_heart_train, iter=2000, warmup=500)}
# chains is number of sample paths from posterior; iter is number of samples within a chain; warmup is number of iterations to discard
A summary of the model below. “Sigma” is the standard deviation of the errors; “mean_PPD” is the mean of the posterior predictive samples.MCMC diagnostics - “RHat” is a measure of within chain variance compared to across chain variance (<1.1 implies convergence); “log-posterior” is similar to likelihood.
not_run_sample_only <- function(){print(summary(model_bayes_glm),digits=4)}
The stan model used default normal priors for intercepts and coefficients. Default priors are automatically scaled to limit how informative they are - below we can see the adjusted (scaled) prior for the coefficients differs from the default 2.5:
# summary of priors
not_run_sample_only <- function(){print(prior_summary(model_bayes_glm),digits=4)}
Credible intervals express the probability that a parameter falls within a given range (vs a confidence interval which is the probability that a range contains the true value of the parameter). These credible intervals are computed by finding the relevant quantiles of the draws from the posterior distribution. They produce similar ranges to the confidence intervals from the frequentist approach.
confint(final_model_glm, level=0.95)
not_run_sample_only <- function(){posterior_interval(model_bayes_glm, prob=0.95)}
Waiting for profiling to be done...
| 2.5 % | 97.5 % | |
|---|---|---|
| (Intercept) | -8.83403551 | -5.95320077 |
| AGE | 0.07229529 | 0.11228084 |
| SEX | -1.41856263 | -0.75773533 |
| PREVHYP | 0.28161591 | 0.97470859 |
| DIABETES | -0.03837607 | 1.07525870 |
| TOTCHOL | -0.00110349 | 0.00577671 |
Adjusting scales and changing priors#
stan_glm allows a selection of prior distributions for the coefficients, intercept, and auxiliary parameters. The prior distributions can be altered by specifying different locations/scales/dfs, but all the prior take the form of a single chosen probability distribution.
Some drivers for wanting to specify a prior:
Available information/ research might suggest a base value for our parameters. Particularly valuable if our own observed data is sparse.
We may not have a good idea of the value, but know that it is constrained in some way e.g. is positive.
The scale is the standard deviation of the prior. As noted earlier, the model autoscales to ensure priors are not too informative. We can turn this off when we specify our own priors. Documentation on choice of priors is here.
To allow for varying distributions across the priors, we need to define the model in STAN or JAGS. See the linear regression example below for an example of this in JAGS.
Specifying our own priors below. Little impact on the posterior estimates.
not_run_sample_only <- function(){model_bayes_glm_scale <- stan_glm(PREVCHD ~ AGE + SEX + PREVHYP + DIABETES + TOTCHOL, family = "binomial",data=df_heart_train, iter=2000, warmup=500,
prior_intercept = normal(location = 0, scale = 10, autoscale = FALSE),
prior = normal(location = 0, scale = 5, autoscale = FALSE),
prior_aux = exponential(rate = 1, autoscale = FALSE)
)
print(summary(model_bayes_glm_scale),digits=4)}
Model fit#
We are able to extract predictions from each iteration of the posterior sampling. We can extract predictions for new data. Could be tested against the observations for goodness of fit. The follwing from the rstanarm manual, p43:
“The posterior predictive distribution (posterior_predict) is the distribution of the outcome implied by the model after using the observed data to update our beliefs about the unknown parameters in the model. Simulating data from the posterior predictive distribution using the observed predictors is useful for checking the fit of the model. Drawing from the posterior predictive distribution at interesting values of the predictors also lets us visualize how a manipulation of a predictor affects (a function of)the outcome(s). With new observations of predictor variables we can use the posterior predictive distribution to generate predicted outcomes.”
not_run_sample_only <- function(){posteriors <- posterior_predict(model_bayes_glm,newdata=df_heart_test)
posterior <- as.data.frame(posteriors) # each column is a data point from the dataset and each row is a prediction
# Print 10 predictions for 5 lives
print("10 predictions for 5 lives")
posteriors[1:10, 1:5]}
We can plot the posterior distributions for the model parameters from the samples:
not_run_sample_only <- function(){posterior <- as.matrix(model_bayes_glm)
plot1<- mcmc_areas(posterior, pars = c("AGE"), prob = 0.80)
plot2<- mcmc_areas(posterior, pars = c("SEX"), prob = 0.80)
plot3<- mcmc_areas(posterior, pars = c("PREVHYP"), prob = 0.80)
plot4<- mcmc_areas(posterior, pars = c("DIABETES"), prob = 0.80)
plot5<- mcmc_areas(posterior, pars = c("TOTCHOL"), prob = 0.80)
grid.arrange(plot1,plot2, plot3, plot4, plot5, top="Posterior distributions (median + 80% intervals)")}
We can extract the \(R^2\) from the posterior distribution and plot:
not_run_sample_only <- function(){r2_posterior <- bayes_R2(model_bayes_glm)
summary(r2_posterior)
hist(r2_posterior)} #expect normal
Posterior predictive checks can be extracted using “pp_check”
“dens_overlay” - each light blue line represents the distribution of predicted scores from a single replication, and the dark blue line represents the observed data. If the model fits, the dark blue line should align closely with the light blue lines.
“stat” in the “pp_check” function, we can get a distribution of the mean of the dependent variable from all replications. These are the light blue bars: the means from each replication plotted as a histogram. The mean from the observed data is then plotted on top as a dark blue bar.
Here the outcome is binary so the density overlay outcomes are concentrated at one or zero.
not_run_sample_only <- function(){pp_check(model_bayes_glm, "stat")
pp_check(model_bayes_glm, "dens_overlay")}
Further considerations: The loo package provides “efficient approximate leave-one-out cross-validation (LOO), approximate standard errors for estimated predictive errors (including comparisons), and the widely applicable information criterion (WAIC).The loo package can be used to estimate predictive error of any MCMC item-level log likelihood output”.
Regression - linear#
The above example looked at a binary response. In this example we’ll look at predicting a continuous variable using data on my household electricity consumption over 2016-2021. The above example used stan_glm in RSTANARM. Here we will use a model defined in RJAGS with additional flexibility around the choice of priors, which is also possible in a paramaterised model for STAN. RJAGS combines the power of R with the “Just Another Gibbs Sampler” or “JAGS” engine. To get started, first download the “JAGS” program, then set up the packages as above.
Both JAGS and STAN allow for the parameterisation of a range of different models. The example below was chosen for comparison with a conventional GLM approach.
Data prep:
Daily electricity usage for a household in Sydney over 2019-21. Rows represent half hourly readings/ estimates.
Data are grouped into daily usage.
Also includes are temperatures, sunlight and rainfall data for the area taken from BOM.
Calculated fields for weekdays vs weekends, seasons and a post-covid working from home indicator.
df_usage <- read.csv(file = '../_static/bayesian_applications/elec_usage.csv')
df_usage <- df_usage %>% mutate(Date = as.Date(Date, format="%Y-%m-%d"), EndDate = parse_date_time(EndDate, '%Y-%m-%d %H:%M:%S'), StartDate = parse_date_time(StartDate, '%Y-%m-%d %H:%M:%S'))
df_usage <- df_usage[c(-2,-3,-4,-6)] %>% # drop start and end dates, rate type, duration
group_by(Date) %>% summarise(Usage = sum(Usage), MaxTemp = max(MaxTemp), MinTemp = min(MinTemp), Rain_mm = max(Rain_mm), Solar_Exposure = max(Solar_Exposure)) %>%
# Add in fields to identify seasons, weekend/ weekday and an indicator for the post-covid/ work from home period
mutate(Season=
if_else(month(Date)>= 3 & month(Date) < 6,"Autumn",
if_else(month(Date)>= 6 & month(Date) < 9,"Winter",
if_else(month(Date)>= 9 & month(Date) < 12,"Spring","Summer"))),
Covid_Ind=if_else(Date>= "2020-03-15",1,0),
Weekend=
if_else(wday(Date)==7 | wday(Date)==1,1,0))
df_usage$Season <- factor(df_usage$Season, levels = c("Summer","Autumn","Winter","Spring")) # change season levels
head(df_usage)
| Date | Usage | MaxTemp | MinTemp | Rain_mm | Solar_Exposure | Season | Covid_Ind | Weekend |
|---|---|---|---|---|---|---|---|---|
| 2019-12-21 | 21.064 | 26.7 | 21.0 | 0.0 | 27.1 | Summer | 0 | 1 |
| 2019-12-22 | 9.529 | 19.9 | 18.6 | 0.0 | 11.9 | Summer | 0 | 1 |
| 2019-12-23 | 15.739 | 22.1 | 17.2 | 0.0 | 14.4 | Summer | 0 | 0 |
| 2019-12-24 | 18.652 | 24.0 | 18.6 | 1.8 | 18.3 | Summer | 0 | 0 |
| 2019-12-25 | 18.924 | 23.2 | 21.6 | 0.2 | 27.8 | Summer | 0 | 0 |
| 2019-12-26 | 14.584 | 23.6 | 21.4 | 0.0 | 30.8 | Summer | 0 | 0 |
Data is mostly complete:
introduce(df_usage)
plot_intro(df_usage)
plot_missing(df_usage)
| rows | columns | discrete_columns | continuous_columns | all_missing_columns | total_missing_values | complete_rows | total_observations | memory_usage |
|---|---|---|---|---|---|---|---|---|
| 732 | 9 | 2 | 7 | 0 | 23 | 709 | 6588 | 53464 |
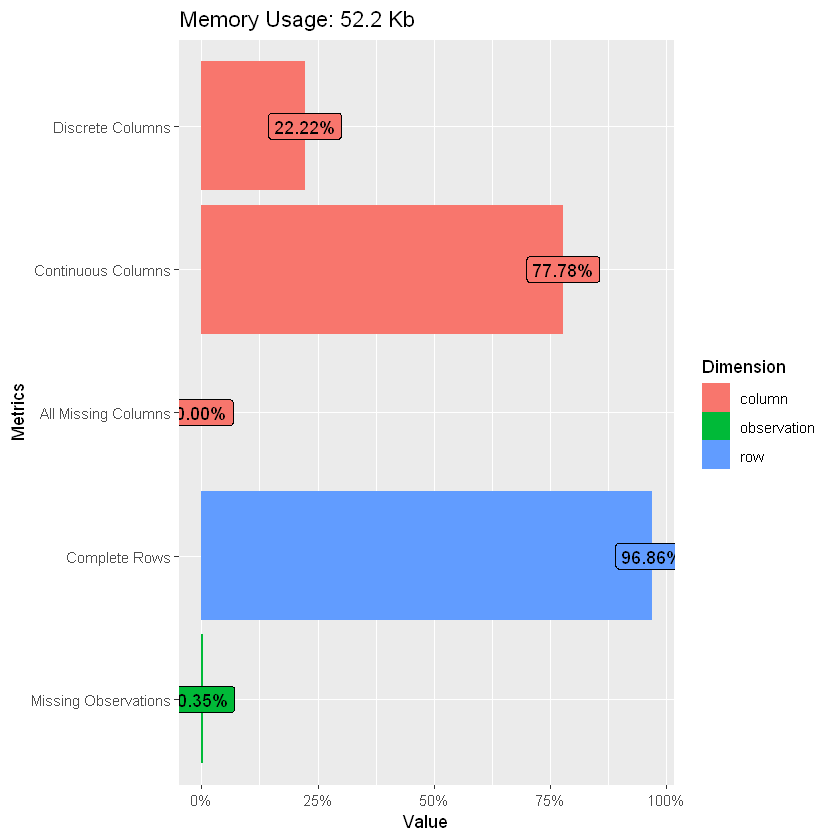
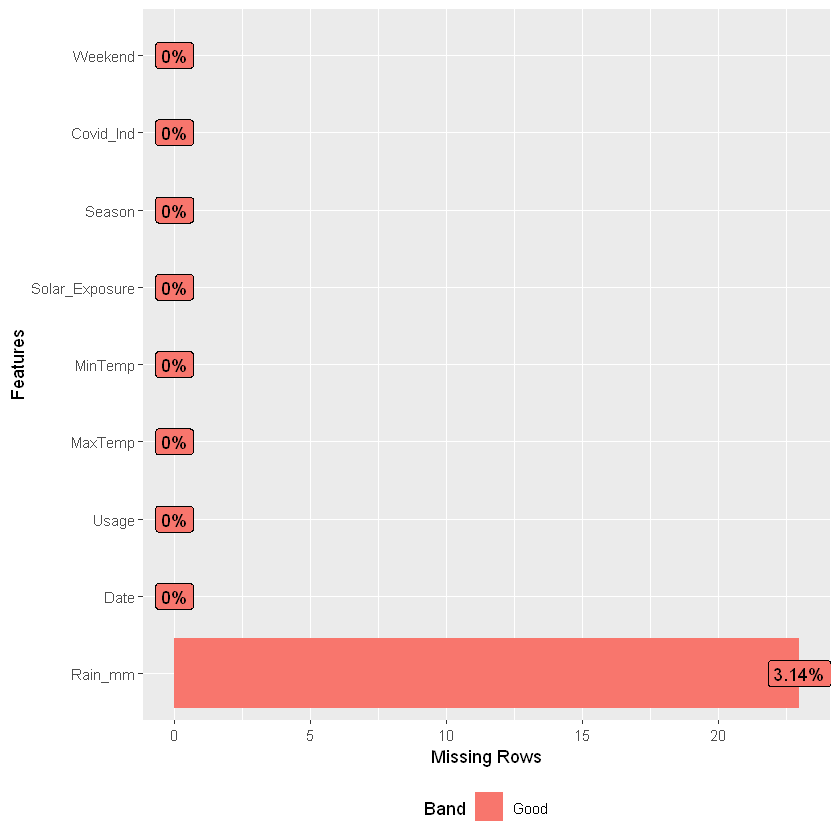
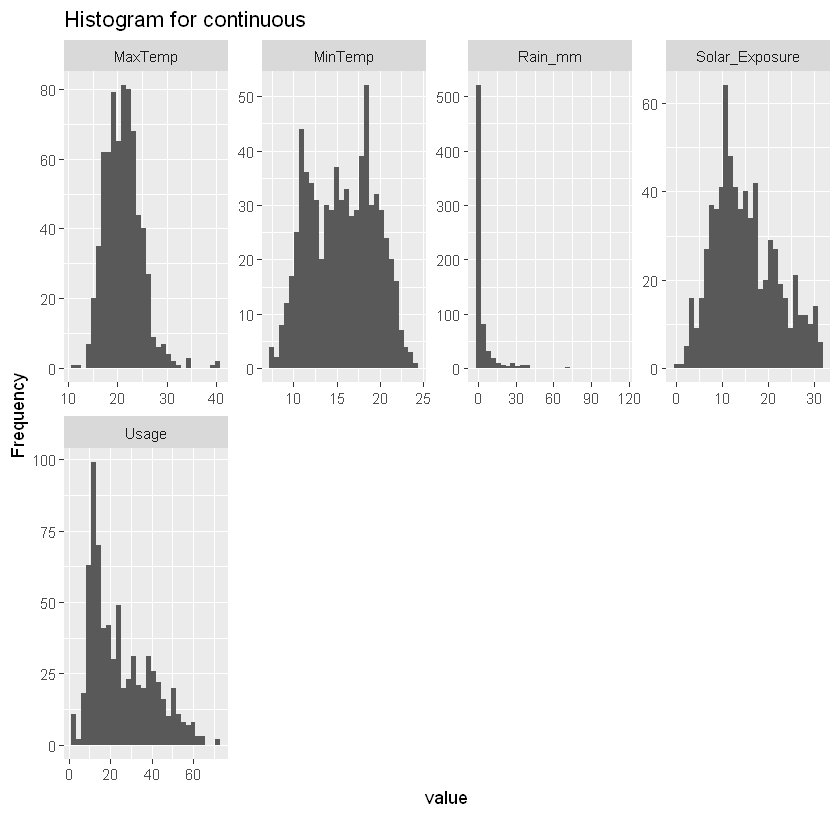
Drop records with NAs as they are few, also only include non-zero usage, review explanatory variables; Gamma dist potentially a better fit than normal for Usage given the skewness in the tail; alternatively use normal with a log link.
df_usage <- na.omit(df_usage)
df_usage <- df_usage %>% filter(Usage>0)
plot_bar(df_usage, title="Barplot")
plot_histogram(df_usage, title="Histogram for continuous")
qq_data <- df_usage[,c("MaxTemp", "MinTemp", "Solar_Exposure", "Usage")]
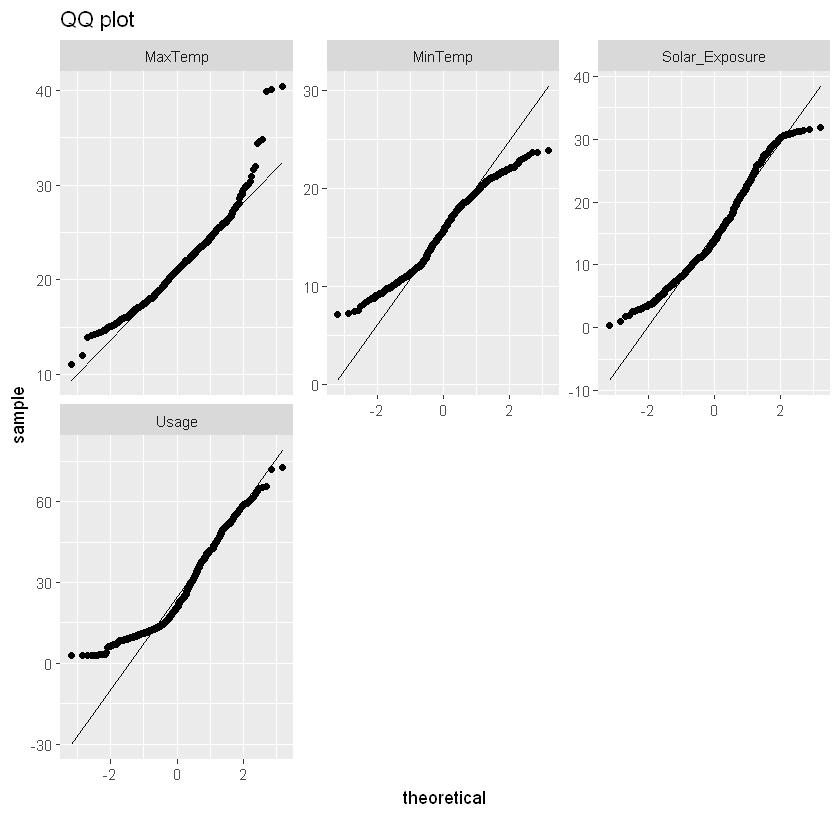
plot_qq(qq_data, title="QQ plot")
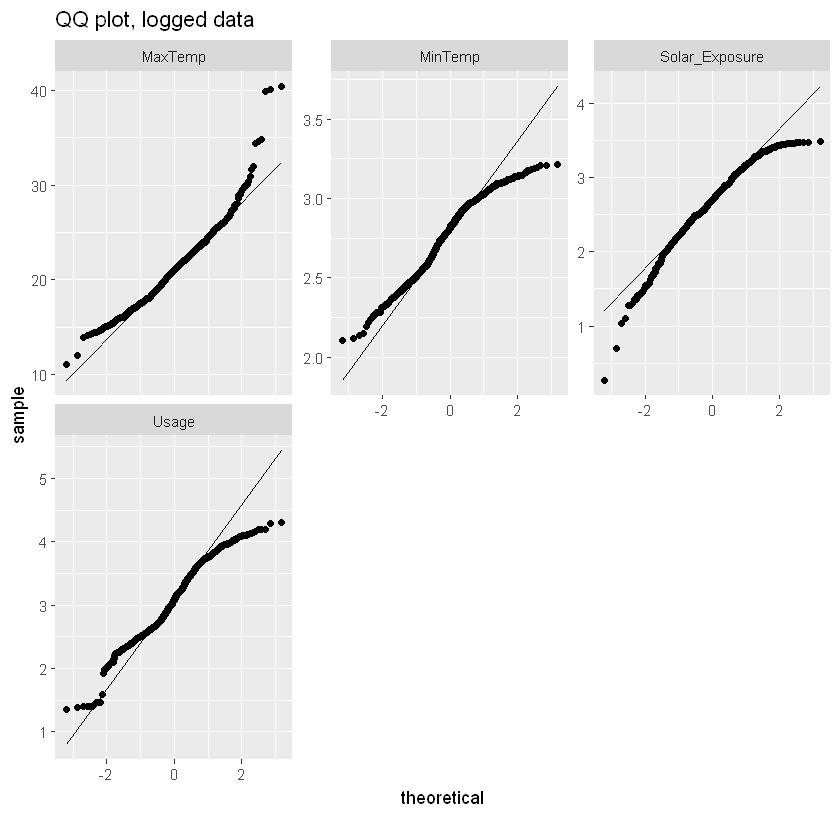
log_qq_data <- update_columns(qq_data, 2:4, function(x) log(x + 1))
plot_qq(log_qq_data, title="QQ plot, logged data")
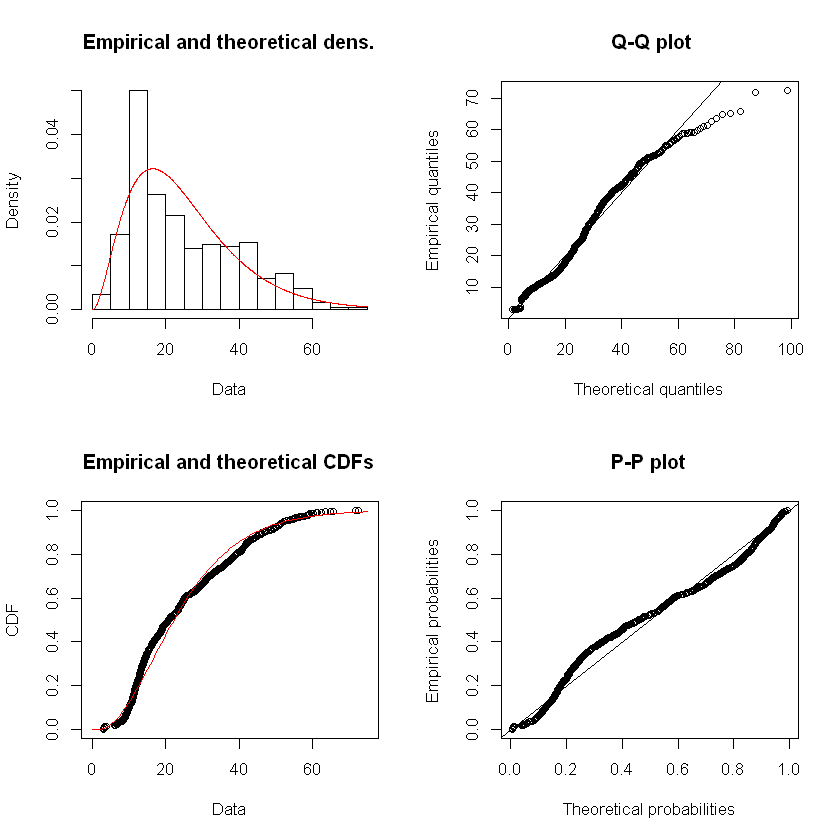
usage_fit_gamma <- fitdist(df_usage$Usage, distr = "gamma", method = "mme")
summary(usage_fit_gamma)
plot(usage_fit_gamma)
1 columns ignored with more than 50 categories.
Date: 707 categories
Fitting of the distribution ' gamma ' by matching moments
Parameters :
estimate
shape 2.9114935
rate 0.1164095
Loglikelihood: -2813.89 AIC: 5631.78 BIC: 5640.902
Usage correlated with season, max/min temp and covid wfh indicator. Max and Min Temps are not surprisingly highly correlated with one another, with the seasons and with solar exposure.
plot_correlation(na.omit(df_usage))
1 features with more than 20 categories ignored!
Date: 707 categories
Split data into training and testing data sets:
# Create a random sample of row IDs
sample_rows <- sample(nrow(df_usage),0.75*nrow(df_usage))
# Create the training dataset
df_usage_train <- df_usage[sample_rows,]
# Create the test dataset
df_usage_test <- df_usage[-sample_rows,]
Fit a simple GLM using all variables:
full_model_glm <- glm(Usage~.,data=df_usage_train[-1], gaussian(link="log"))
summary(full_model_glm)
Call:
glm(formula = Usage ~ ., family = gaussian(link = "log"), data = df_usage_train[-1])
Deviance Residuals:
Min 1Q Median 3Q Max
-46.096 -4.220 0.013 4.539 50.118
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 5.398e+00 2.017e-01 26.766 < 2e-16 ***
MaxTemp -2.440e-02 8.537e-03 -2.858 0.00444 **
MinTemp -9.728e-02 9.487e-03 -10.254 < 2e-16 ***
Rain_mm -2.596e-06 1.343e-03 -0.002 0.99846
Solar_Exposure -1.989e-02 3.765e-03 -5.283 1.87e-07 ***
SeasonAutumn 7.897e-02 8.573e-02 0.921 0.35740
SeasonWinter 4.277e-02 9.590e-02 0.446 0.65579
SeasonSpring 8.101e-02 8.540e-02 0.949 0.34326
Covid_Ind -2.651e-02 1.103e-01 -0.240 0.81007
Weekend -4.936e-02 3.338e-02 -1.479 0.13983
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for gaussian family taken to be 86.41346)
Null deviance: 118331 on 529 degrees of freedom
Residual deviance: 44933 on 520 degrees of freedom
AIC: 3879.3
Number of Fisher Scoring iterations: 8
Use stepwise regression to reduce the explanatory variables:
# specify a null model with no predictors
null_model_glm <- glm(Usage ~ 1, data = df_usage_train, gaussian(link="log"))
# use a forward stepwise algorithm to build a parsimonious model
step_model_glm <- step(null_model_glm, scope = list(lower = null_model_glm, upper = full_model_glm), direction = "forward")
Summary of the model:
summary(step_model_glm)
Call:
glm(formula = Usage ~ MinTemp + Solar_Exposure + MaxTemp + Weekend,
family = gaussian(link = "log"), data = df_usage_train)
Deviance Residuals:
Min 1Q Median 3Q Max
-46.465 -4.196 0.078 4.629 49.779
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 5.396219 0.096133 56.133 < 2e-16 ***
MinTemp -0.095761 0.007011 -13.659 < 2e-16 ***
Solar_Exposure -0.019246 0.003249 -5.923 5.73e-09 ***
MaxTemp -0.024253 0.008169 -2.969 0.00313 **
Weekend -0.049882 0.033198 -1.503 0.13355
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for gaussian family taken to be 85.9083)
Null deviance: 118331 on 529 degrees of freedom
Residual deviance: 45101 on 525 degrees of freedom
AIC: 3871.3
Number of Fisher Scoring iterations: 7
For simplicity, we’ll assume a model defined by MaxTemp and MinTemp only, noting the significant correlation with other explanatory variables.
gamma_model_glm <- glm(Usage ~ MaxTemp + MinTemp, family = Gamma(link="inverse"), data = df_usage_train)
summary(final_model_glm)
Call:
glm(formula = PREVCHD ~ AGE + SEX + PREVHYP + DIABETES + TOTCHOL,
family = "binomial", data = df_heart_train)
Deviance Residuals:
Min 1Q Median 3Q Max
-1.1702 -0.4182 -0.2772 -0.1830 3.0145
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -7.371509 0.734203 -10.040 < 2e-16 ***
AGE 0.091994 0.010190 9.028 < 2e-16 ***
SEX -1.084013 0.168352 -6.439 1.2e-10 ***
PREVHYP 0.622003 0.176473 3.525 0.000424 ***
DIABETES 0.543020 0.282690 1.921 0.054744 .
TOTCHOL 0.002377 0.001755 1.354 0.175643
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 1366.6 on 2678 degrees of freedom
Residual deviance: 1198.5 on 2673 degrees of freedom
AIC: 1210.5
Number of Fisher Scoring iterations: 6
Changing the family to gaussian with log link (later graph shows little change in predictions, although AIC is higher). Select gaussian for ease of comparison with the Bayes model.
final_model_glm <- glm(Usage ~ MaxTemp + MinTemp, family = gaussian(link="log"), data = df_usage_train)
summary(final_model_glm)
Call:
glm(formula = Usage ~ MaxTemp + MinTemp, family = gaussian(link = "log"),
data = df_usage_train)
Deviance Residuals:
Min 1Q Median 3Q Max
-51.898 -4.306 -0.382 5.030 48.100
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 5.414631 0.099962 54.167 < 2e-16 ***
MaxTemp -0.041520 0.007992 -5.195 2.93e-07 ***
MinTemp -0.092090 0.007316 -12.587 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for gaussian family taken to be 92.09666)
Null deviance: 118331 on 529 degrees of freedom
Residual deviance: 48534 on 527 degrees of freedom
AIC: 3906.2
Number of Fisher Scoring iterations: 6
Extract coefficients:
final_model_glm_coeff <- as.data.frame(coef(final_model_glm))
final_model_glm_coeff
| coef(final_model_glm) | |
|---|---|
| (Intercept) | 5.41463097 |
| MaxTemp | -0.04152022 |
| MinTemp | -0.09209007 |
Project the result for a dummy record showing the link:
print("Dummy prediction with min of 10 and max of 20:")
predict(final_model_glm, newdata= as.data.frame(cbind(MaxTemp=20,MinTemp=10)), # model and data
type="response", # or terms for coefficients
se.fit = FALSE)
# replicate
exp(final_model_glm_coeff[1,] + final_model_glm_coeff[2,]*20+final_model_glm_coeff[3,]*10)
[1] "Dummy prediction with min of 10 and max of 20:"
Adding the predictions to the test data:
# predictions, normal
pred_usage <- as.data.frame(
predict(final_model_glm, newdata= df_usage_test, # model and data
type="response", # or terms for coefficients
se.fit = TRUE, # default is false
interval = "confidence", #default "none", also "prediction"
level = 0.95
)
)
# predictions, gamma
usage_pred_gamma <-
predict(gamma_model_glm, newdata= df_usage_test, # model and data
type="response", # or terms for coefficients
se.fit = FALSE, # default is false
)
# rename
pred_usage <- rename(pred_usage,usage_pred=fit,se_usage_pred=se.fit)
# add back to data
df_usage_test_pred <- cbind(df_usage_test,pred_usage, usage_pred_gamma)
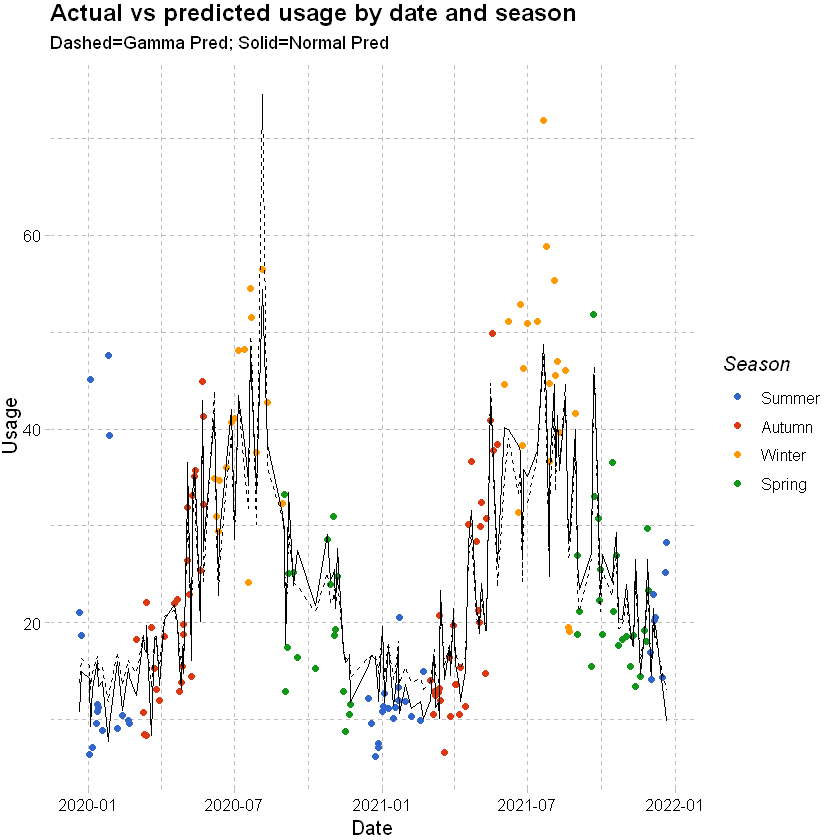
Plotting the results shows a poorer fit for winter when the usage spikes and in instances with outlier temperatures. Predictions for the test data are not hugely different to the gamma family model.
df_usage_test_pred %>%
ggplot() +
geom_point(aes(x=Date,y=Usage,color=Season)) +
# add a modeled line
geom_line(aes(x=Date,y=usage_pred)) +
geom_line(aes(x=Date,y=usage_pred_gamma), linetype = "dashed") +
labs(x="Date", y="Usage", title = "Actual vs predicted usage by date and season",subtitle="Dashed=Gamma Pred; Solid=Normal Pred") +
theme_pander() + scale_color_gdocs()
# plot temperatures
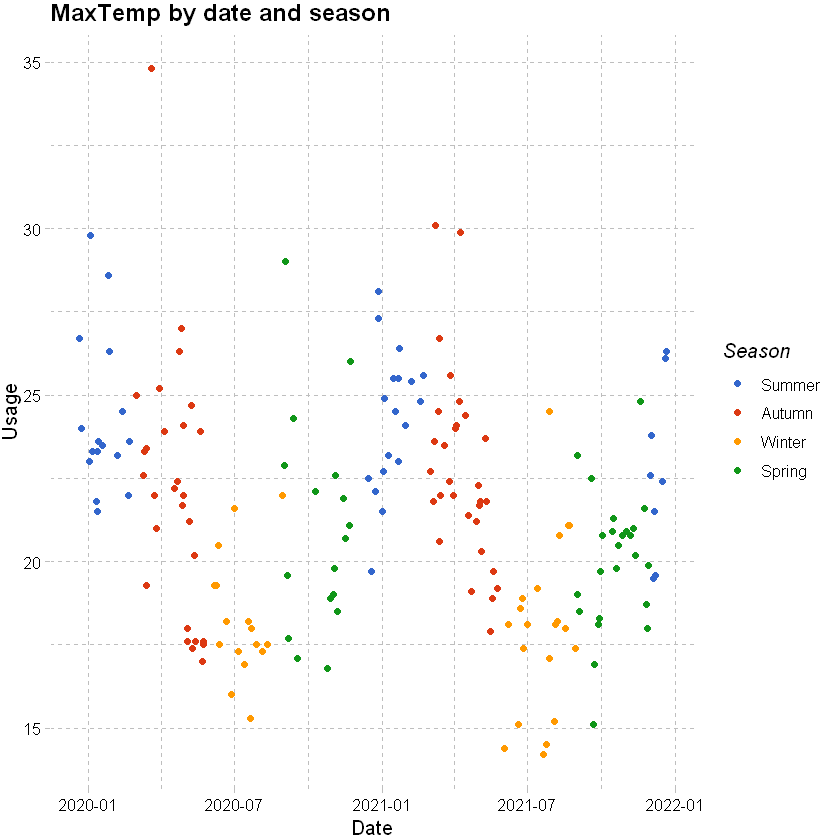
df_usage_test_pred %>%
ggplot() +
geom_point(aes(x=Date,y=MaxTemp,color=Season)) +
labs(x="Date", y="Usage", title = "MaxTemp by date and season") +
theme_pander() + scale_color_gdocs()
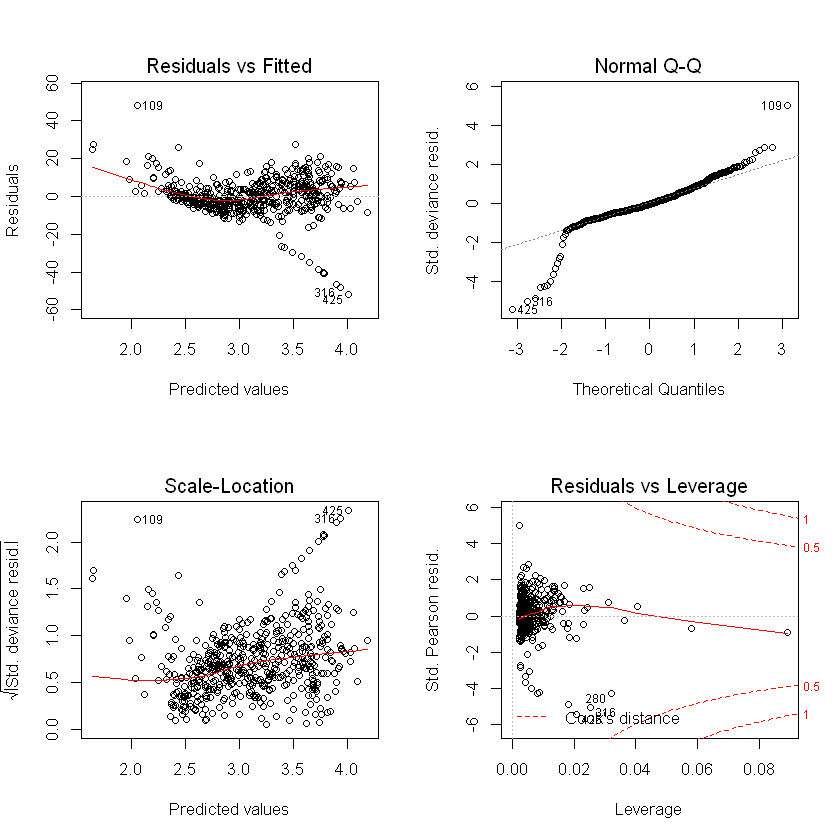
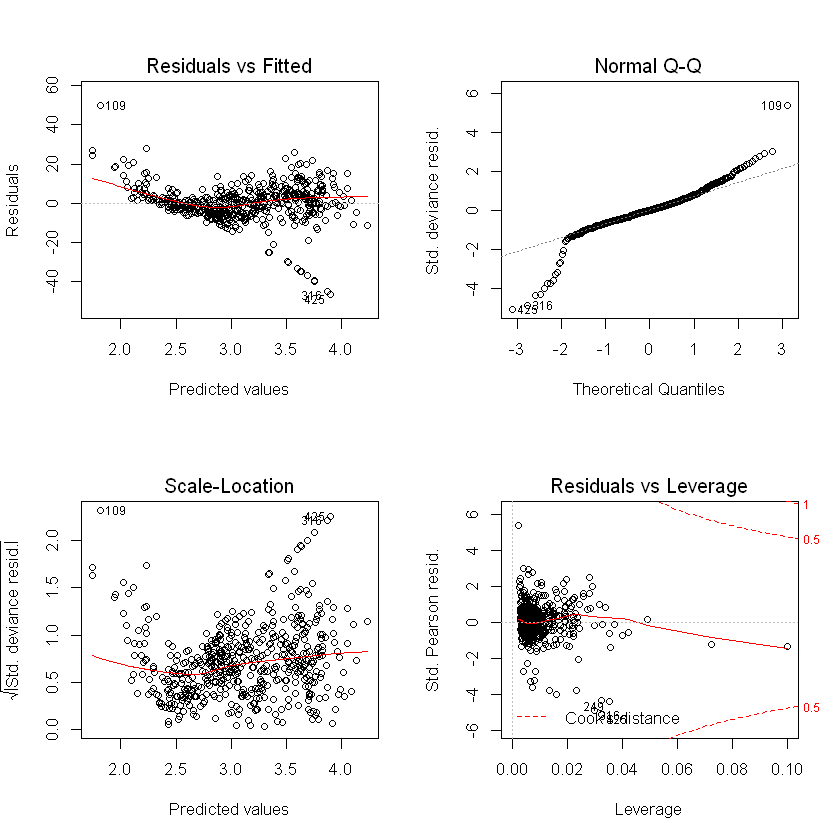
Plots show slightly higher residuals at higher predicted values for the step regression model and final selected. QQ plot suggests skewness in the data, which we could see earlier in the histogram of usage.
par(mfrow = c(2, 2))
plot(final_model_glm)
plot(step_model_glm)
Define a regression model in RJAGS. The structure here is more flexible than stan_glm which is predefined. This allows for a wider selection of prior distributions and a mixture of modeling choices. Also possible to specify model forms in this way for STAN.
\(Y_i \propto N(m_i,s^2)\)
Where
\(m_i = a + bX_1i +cX_2i\)
\(a, b, c and s\) have some assumed prior distributions.
Note that the distribution syntax is slightly different to R, for example in R a normal distribution is specified using the mean and standard deviation, but in JAGS the second parameter of the dnorm command is the distribution’s precision (1 / variance).
usage_model <- "model{
#Likelihood model for Y[i]
for (i in 1:length(Y)) {
Y[i] ~ dnorm(m[i], s^(-2)) # link=log
log(m[i]) <- a + b*X_1[i] + c*X_2[i]
}
# Prior models for a, b, c, s
a ~ dnorm(0, 0.001) # Intercept
b ~ dnorm(0, 0.001) # MaxTemp
c ~ dnorm(0, 0.001) # MinTemp
s ~ dunif(0, 10) # Error
}"
Simulate from the model:
burn-in period of 2k iterations aims for convergence and throws away these earlier test samples.
10k iterations for 3 chains.
saving every 10th sample only in order to save space.
usage_sim <- jags.model(textConnection(usage_model),
data=list(Y = df_usage_train$Usage, X_1 = df_usage_train$MaxTemp, X_2 = df_usage_train$MinTemp),
n.chains = 3)
usage_posterior <- coda.samples(usage_sim,
variable.names = c("a","b","c","s"),
n.iter = 10000, n.burnin = 2000, n.thin = 10, DIC = F)
Compiling model graph
Resolving undeclared variables
Allocating nodes
Graph information:
Observed stochastic nodes: 530
Unobserved stochastic nodes: 4
Total graph size: 3458
Initializing model
Summary of the results below:
The mean of the
bchain value was -0.040. This is an estimate of the posterior mean ofb. This is consistent with the GLM aboveThe corresponding naive standard error, 0.000253, measures the potential error in this estimate. This error is calculated by dividing the standard deviation of the
bchain values by the square root of the number of iterations (or sample size). This is a naive approach to calculating error in a setting with dependent samples.
Also showing the density plots for the posteriors as well as the trace plots for each of the chains.
summary(usage_posterior)
plot(usage_posterior,trace=FALSE)
par(mfrow = c(2, 2))
plot(usage_posterior,density=FALSE)
Iterations = 1001:11000
Thinning interval = 1
Number of chains = 3
Sample size per chain = 10000
1. Empirical mean and standard deviation for each variable,
plus standard error of the mean:
Mean SD Naive SE Time-series SE
a 5.42368 0.107372 6.199e-04 0.0073562
b -0.04263 0.008776 5.067e-05 0.0009216
c -0.09124 0.007518 4.341e-05 0.0004607
s 9.55992 0.244700 1.413e-03 0.0018704
2. Quantiles for each variable:
2.5% 25% 50% 75% 97.5%
a 5.21873 5.34977 5.42454 5.49497 5.63821
b -0.06033 -0.04832 -0.04240 -0.03661 -0.02634
c -0.10548 -0.09641 -0.09151 -0.08617 -0.07628
s 9.04907 9.39190 9.57360 9.74782 9.96562
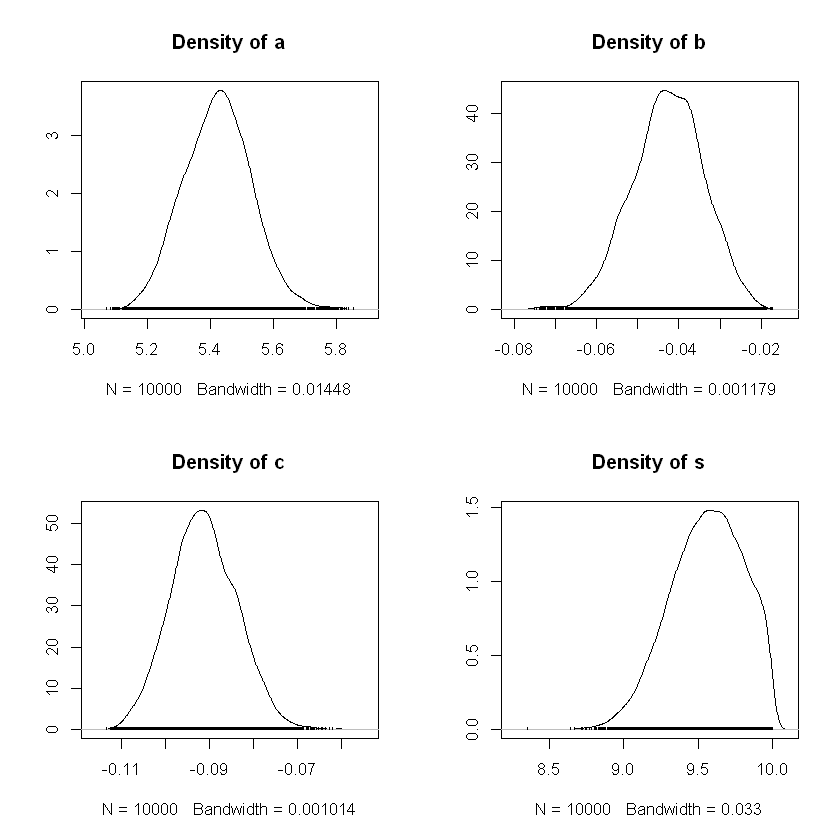
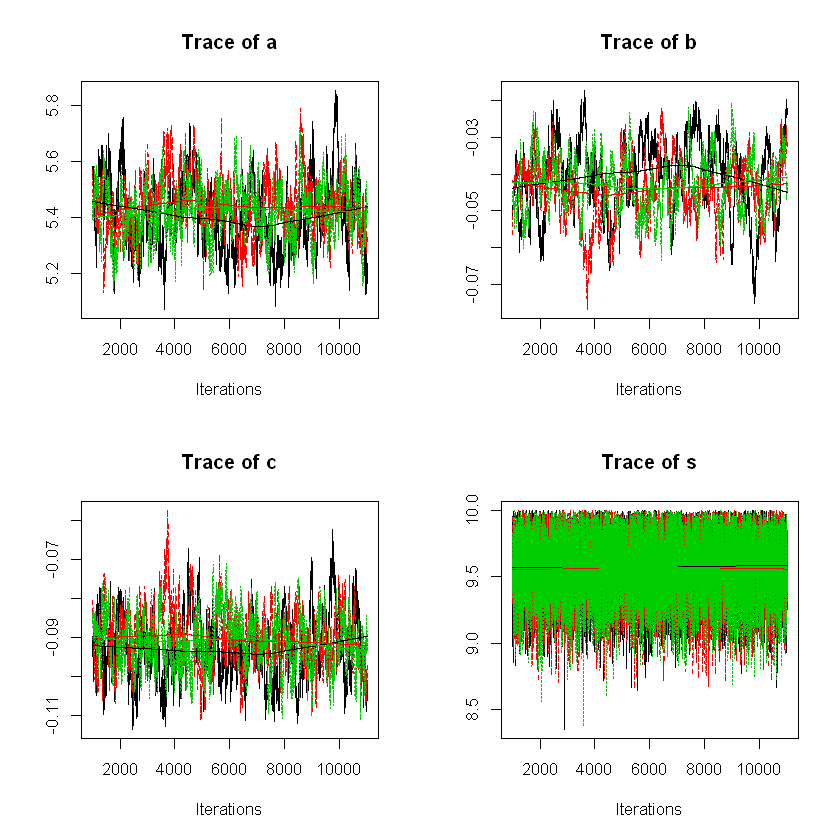
We can plot the posterior distributions for the model parameters from the samples:
posterior <- as.matrix(usage_posterior)
plot1<- mcmc_areas(posterior, pars = c("a"), prob = 0.80)
plot2<- mcmc_areas(posterior, pars = c("b"), prob = 0.80)
plot3<- mcmc_areas(posterior, pars = c("c"), prob = 0.80)
plot4<- mcmc_areas(posterior, pars = c("s"), prob = 0.80)
grid.arrange(plot1,plot2, plot3, plot4, top="Posterior distributions (median + 80% intervals)")
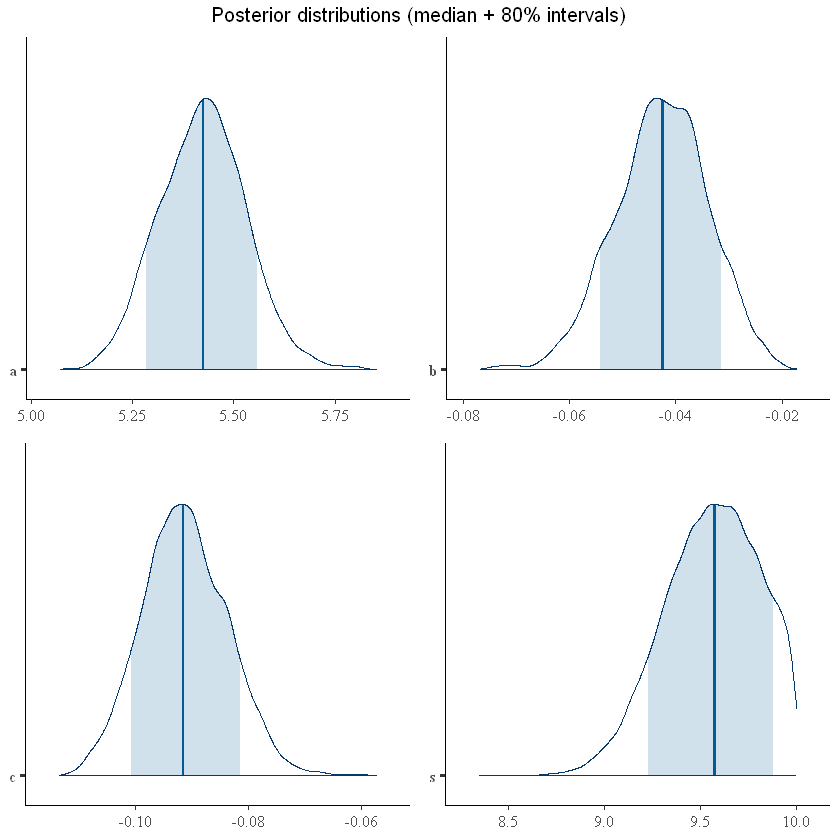
Similar to the earlier example, we could extract the \(R^2\) from the posterior distribution as well as run posterior predictive checks.
Further considerations: extracting the mean of the parameter projections, we could produce predictions for the test data. We could also produce predictions for test data point based upon each of the samples from the posterior, so above we would produce 2400 predictions for each data point (3x10k, discarding the first 2k from each chain and only saving 1/10 of the samples).
Estimating COVID 19 infections in NSW, Australia#
This paper presented at the 2021 Actuaries (Institute) Summit discusses a method of forecasting COVID infections using the package “epinow2”. The package makes use of STAN.
“[Epinow2] estimates the time-varying reproduction number on cases by date of infection… Imputed infections are then mapped to observed data (for example cases by date of report) via a series of uncertain delay distributions…”
That is to say, the model makes some assumptions about lags in symptoms and in reporting (assuming some distribution for those delays) in order to estimate the true underlying number of infections (backwards). Using that backcast it projects out how those infections might be reported over time. The model also estimates the effective reproduction number in order to predict future infections.
Covid case and test data sourced from the department of NSW Website on 17/01/2022.
We should be careful in placing too heavy a reliance on any models of incidence which are based upon case data (particularly where case rates are expected to be under reported or where testing is incomplete). The example is purely illustrative and does not attempt to correct for gaps in the data.
Case data:
df_cases <- read.csv(file = '../_static/bayesian_applications/confirmed_cases_table1_location.csv')
head(df_cases)
df_tests <- read.csv(file = '../_static/bayesian_applications/pcr_testing_table1_location_agg.csv')
head(df_tests)
# cases
df_cases <- df_cases %>% mutate(descr="cases",date=as.Date(notification_date),cases=1) %>%
filter(date > "2021-04-30",date <= "2021-12-31") %>%
group_by(date, descr) %>%
summarise(confirm=sum(cases))
head(df_cases)
| notification_date | postcode | lhd_2010_code | lhd_2010_name | lga_code19 | lga_name19 |
|---|---|---|---|---|---|
| 2020-01-25 | 2134 | X700 | Sydney | 11300 | Burwood (A) |
| 2020-01-25 | 2121 | X760 | Northern Sydney | 16260 | Parramatta (C) |
| 2020-01-25 | 2071 | X760 | Northern Sydney | 14500 | Ku-ring-gai (A) |
| 2020-01-27 | 2033 | X720 | South Eastern Sydney | 16550 | Randwick (C) |
| 2020-03-01 | 2077 | X760 | Northern Sydney | 14000 | Hornsby (A) |
| 2020-03-01 | 2163 | X710 | South Western Sydney | 12850 | Fairfield (C) |
| test_date | postcode | lhd_2010_code | lhd_2010_name | lga_code19 | lga_name19 | test_count |
|---|---|---|---|---|---|---|
| 2020-01-01 | 2038 | X700 | Sydney | 14170 | Inner West (A) | 1 |
| 2020-01-01 | 2039 | X700 | Sydney | 14170 | Inner West (A) | 1 |
| 2020-01-01 | 2040 | X700 | Sydney | 14170 | Inner West (A) | 2 |
| 2020-01-01 | 2041 | X700 | Sydney | 14170 | Inner West (A) | 1 |
| 2020-01-01 | 2069 | X760 | Northern Sydney | 14500 | Ku-ring-gai (A) | 1 |
| 2020-01-01 | 2074 | X760 | Northern Sydney | 14500 | Ku-ring-gai (A) | 1 |
`summarise()` has grouped output by 'date'. You can override using the `.groups` argument.
| date | descr | confirm |
|---|---|---|
| 2021-05-01 | cases | 2 |
| 2021-05-02 | cases | 8 |
| 2021-05-03 | cases | 9 |
| 2021-05-04 | cases | 7 |
| 2021-05-05 | cases | 9 |
| 2021-05-06 | cases | 4 |
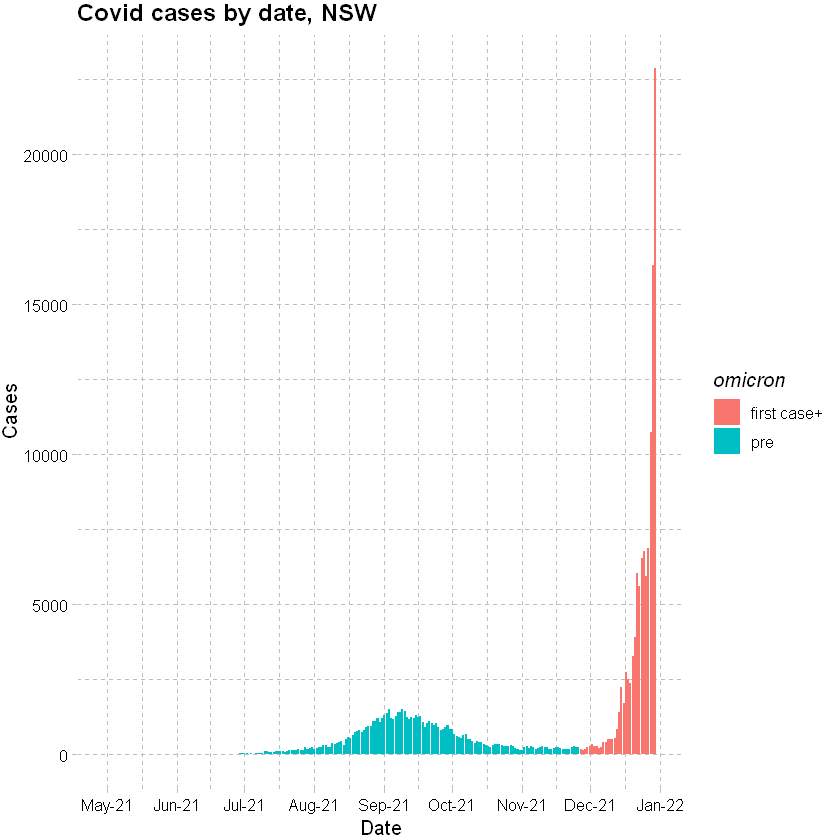
Plotting recorded cases by date (PCR test outcomes only and only to 31 December 2021):
df_cases %>% mutate(omicron=ifelse(date > "2021-11-26","first case+","pre")) %>%
ggplot(data=., mapping = aes(x=date, y=confirm)) +
geom_col(aes(fill=omicron)) +
scale_x_date(date_breaks = "months" , date_labels = "%b-%y", limits = c(as.Date("2021-04-30"), as.Date("2021-12-31"))) +
labs(x="Date", y="Cases", title = "Covid cases by date, NSW") +
theme_pander() + scale_color_gdocs()
Warning message:
"Removed 1 rows containing missing values (geom_col)."
Test data:
df_tests <- df_tests %>% mutate(descr="tests",date=as.Date(test_date)) %>%
filter(date > "2021-04-30",date <= "2021-12-31") %>%
group_by(date, descr) %>%
summarise(tests=sum(test_count))
head(df_tests)
`summarise()` has grouped output by 'date'. You can override using the `.groups` argument.
| date | descr | tests |
|---|---|---|
| 2021-05-01 | tests | 4514 |
| 2021-05-02 | tests | 4775 |
| 2021-05-03 | tests | 14877 |
| 2021-05-04 | tests | 10868 |
| 2021-05-05 | tests | 13126 |
| 2021-05-06 | tests | 24029 |
Plotting tests by date (PCR tests only; to 31 December 2021):
ggplot(data=df_tests, mapping = aes(x=date, y=tests))+
geom_bar(stat="identity") +
scale_x_date(date_breaks = "months" , date_labels = "%b-%y", limits = c(as.Date("2021-04-30"), as.Date("2021-12-31"))) +
labs(x="Date", y="Tests", title = "PCR tests by date, NSW") +
theme_pander() + scale_color_gdocs()
Warning message:
"Removed 1 rows containing missing values (geom_bar)."
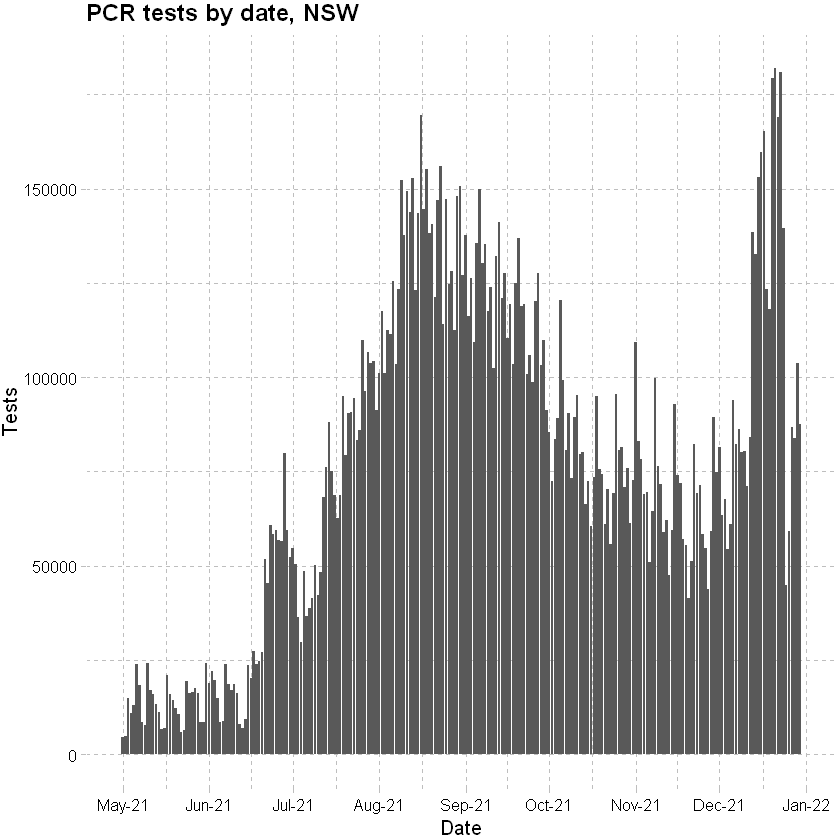
Merged to get positive test rate:
# merge
df <- merge(x = df_cases, y = df_tests, by = "date", all.x = TRUE) %>%
mutate(pos_rate=pmin(1, confirm/tests)) %>%
fill(pos_rate, .direction = "downup") %>%
# add smoothed positive rate
mutate(pos_rate_sm = fitted(loess(pos_rate~as.numeric(date),span=0.1))) # loess - Local Polynomial Regression Fitting; span - the parameter which controls the degree of smoothing
# drop descriptions
df$descr.x <- NULL
df$descr.y <- NULL
Plot of positive rate shows that the proportion of tests returning a positive increases to above 5% from 25th December 2021, suggesting that the case data beyond this point is less complete.
# positive rate
ggplot(data=df, mapping = aes(x=date))+
geom_point(aes(y=(pos_rate))) +
geom_line(aes(y=pos_rate_sm)) +
scale_x_date(date_breaks = "months" , date_labels = "%b-%y", limits = c(as.Date("2021-04-30"), as.Date("2021-12-31"))) +
scale_y_continuous(labels = scales::percent_format(accuracy = 1)) +
labs(x="Date", y="Positive test rate", title = "Positive PCR test rate by date, NSW") +
theme_pander() + scale_color_gdocs()
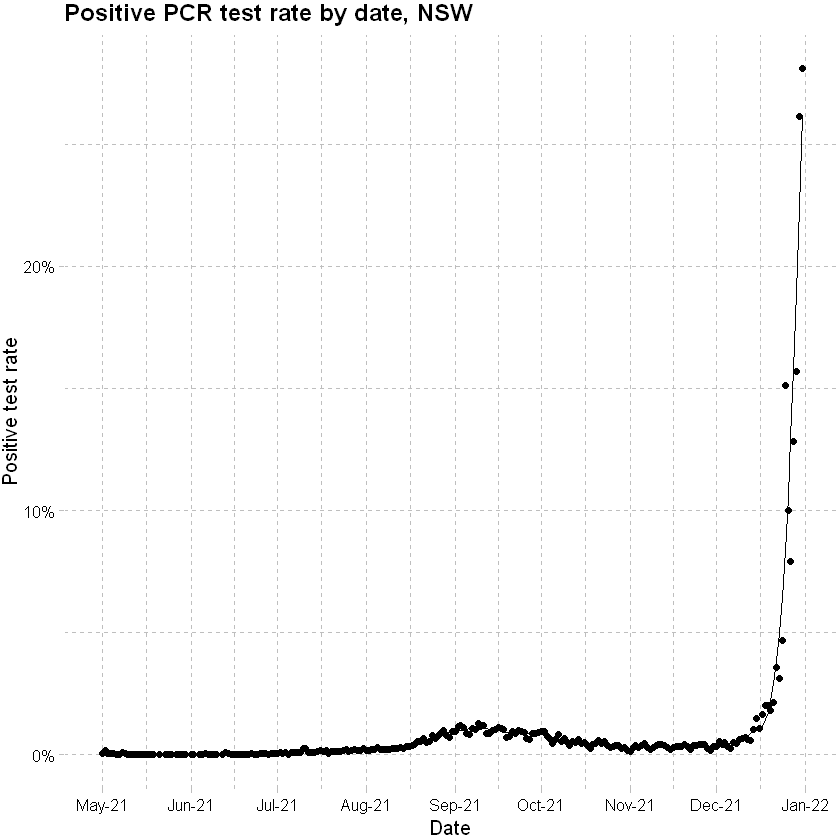
There are some pragmatic methods for adjusting the case numbers for increasing test positivity rates. For our purposes we will focus the model on case data before 23 December 2021 in order to exclude the period where the test data became less reliable/ complete, noting that underlying data completeness issues are likely present.
not_run_sample_only <- function(){# Reporting delays (delay from symptom onset to reporting/ testing positive)
reporting_delay <- estimate_delay(rlnorm(100, log(6), 1), max_value = 15)
cat("Mean reporting delay = ",reporting_delay$mean, "; ")
# Symptom generation time (time between infection events in an infector-infectee pair) and incubation period (time between moment of infection and symptom onset)
generation_time <- get_generation_time(disease = "SARS-CoV-2", source = "ganyani")
cat("Mean generation time =",generation_time$mean, "; ")
incubation_period <- get_incubation_period(disease = "SARS-CoV-2", source = "lauer")
cat("Mean incubation period =",incubation_period$mean, "; ")}
not_run_sample_only <- function(){
df_cases_fit <- df_cases %>% filter(date <= "2021-12-22") # exclude data before 23 December 2021
estimates <- epinow(reported_cases = df_cases_fit[c("date","confirm")], # case data from NSW
generation_time = generation_time,
delays = delay_opts(incubation_period, reporting_delay),
rt = rt_opts(prior = list(mean = 2, sd = 0.2)),
stan = stan_opts(cores = 6, samples = 3000, warmup = 500, chains = 6, control = list(adapt_delta = 0.95)))}
Importing a previous run of the above:
load("../_static/bayesian_applications/covid_estimates_summary.RData")
plot(estimates) produces predefined plots of cases by date reported and date of infection as well as the effective reproduction number. Given the dramatic increase in reported cases towards the end of the period, it is not surprising that the range of forecast cases is wide. Interestingly, the forecast/ partial forecast reproduction number reduces; presumably this is influenced by the earlier observations where case numbers were low. This issue has not been investigated further, however there are articles that discuss the impact of changes to the testing procedures and other limitations.
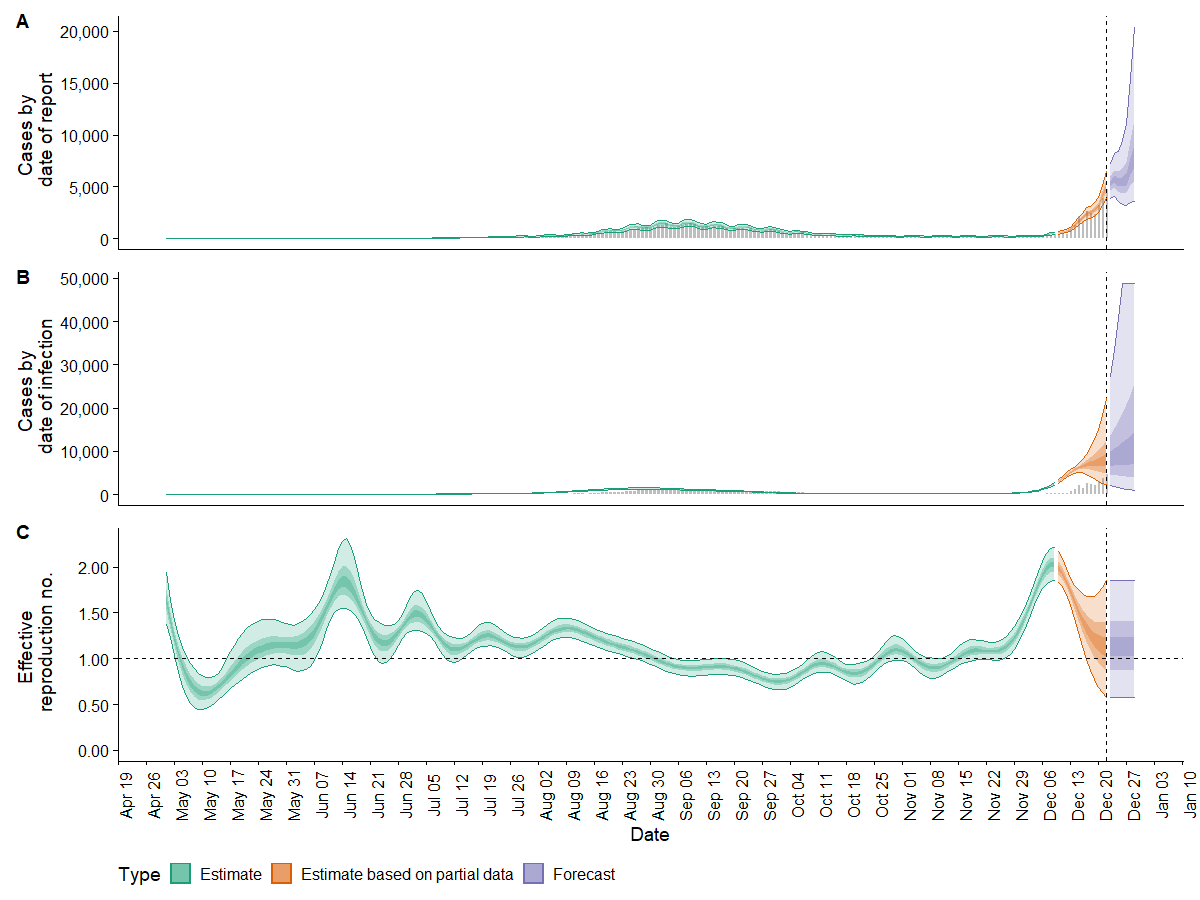 {width=100%}
Merging forecast reported cases with the actual case data:
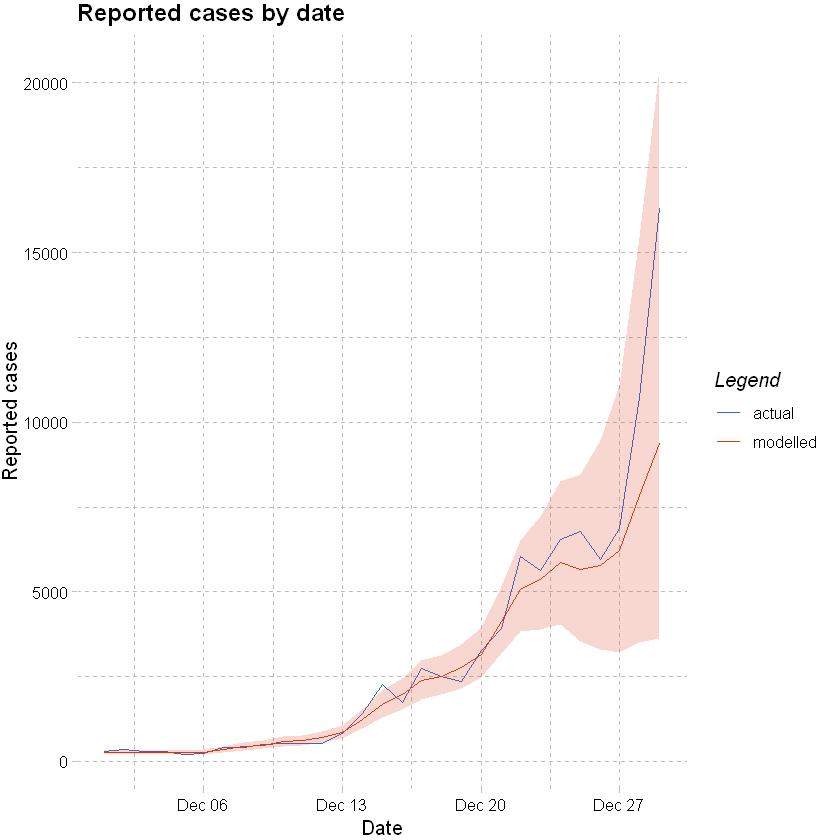
{width=100%}
Merging forecast reported cases with the actual case data:
df <- merge(x = df, y = df_reported, by = "date", all.x = TRUE) %>% filter(date < "2021-12-30")
Plotting forecast vs actuals below - the week to 29 December is fully forecast from the model. Actual cases fall within the projected 90% confidence interval range, noting that the test positivity rate increased materially from 25th December so it is likely that the actual cases are under reported.
colours <- c("actual" = "#3366cc","modelled" = "#dc3912")
ggplot(data=df %>% filter(date >= "2021-12-01"), aes(x=date)) +
geom_line(aes(y=confirm, color="actual")) +
geom_line(aes(y=mean,color="modelled")) +
geom_ribbon(aes(ymin=lower_90, ymax=upper_90), fill="#dc3912", alpha=0.2) +
labs(x="Date", y="Reported cases", title = "Reported cases by date",color="Legend") +
scale_color_manual(values = colours) +
theme_pander()
Common issues in MCMC projections#
Divergent transitions: Common fix is changing the step size using the adapt_delta argument in STAN.
Exceeding maximum tree depth: the is a point of efficiency. See notes here for assistance in STAN and other potential warnings.
Further reading#
A few books and articles of interest on STAN: