Py/R: Multitasking Risk Pricing Using Deep Learning#
By Jacky Poon. Originally published in Actuaries Digital as Analytics Snippet: Multitasking Risk Pricing Using Deep Learning.
So, you have been asked to build a risk premium pricing model for a motor portfolio - a classic GI problem.
The standard approach would be to:
Split the claims into perils, or peril groups based on the cause of loss
Build separate generalised linear models (GLMs) of the frequency and severity of each peril group.
Calibrate non-linear effects such as curves and interactions (typically manually).
This approach has its challenges. Key limitations would be:
Choice of peril groups - finer groups increases granularity, but decreases the data available to each model as they are estimated independently
In the event that frequency and severity are correlated, there is no clear way to model expected cost other than to create a third, independent Tweedie model
Challenges in finding the right interactions and curves based on the data.
What if, there was a model structure that:
Can estimate multiple frequency, severity and expected cost responses in a single model
While sharing commonalities between those outputs
Is a universal approximator so non-linear effects can be captured automatically
Can be expanded to use freeform text, photos, voice, or time series data as inputs?
In this analytics snippet, we introduce multi-task deep learning for general insurance risk pricing.
We apply the flexible structure of deep learning - in particular, multi-task learning, a variation where the model has multiple outputs - to predict all of the expected claims outcomes in a general insurance scenario.
Python and R#
The tutorial below includes code to implement the model, with the option for readers to pick from Python or R.
Python is generally considered to be better for neural network modelling due to its better support for deep learning packages. Consequently it is the recommended language for this snippet and only the output for the Python version is shown. However, R code that implements similar functionality is also included for those who prefer to work exclusively in R. If you are completely new to Python, and feel that the code below a bit intimidating, I would recommend the excellent free introductory tutorial by DataCamp.
Python is free software - you can download it and run it on your pc - either through a distribution which comes with an installer and complete set of packages like Anaconda or a more barebones download directly from python.org. Alternatively, you can also run it online through a web “notebook” interface which works on any device including phones and tablets. Free services includes Google Colaboratory which links in with Google Drive, Microsoft Azure Notebooks which links in with OneDrive, and Binder which links to Github.
Packages#
This example uses keras with Google’s tensorflow library to build the neural networks:
keras, a neural network framework, and
tensorflow Google’s computational library which works with Keras.
Other standard packages include:
pandas, the “panel data” data frames library for python,
numpy for array based calculations,
sci-kit learn, a framework for machine learning,
jupyter, a common tool to viewing and reproducing code
pydot, required to plot the neural network graph, which relies on:
graphwiz. For Graphwiz installation on Windows, you may need to manually add the “bin” subfolder of the installed folder location to your PATH for pydot to access.
Python#
import pandas as pd
import numpy as np
from keras.layers import Input, Embedding, LSTM, Dense, Reshape, concatenate
from keras.models import Model
from keras.utils.vis_utils import model_to_dot
from sklearn.model_selection import train_test_split
from IPython.display import SVG
%matplotlib inline
D:\Anaconda3\lib\site-packages\h5py\__init__.py:36: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.
from ._conv import register_converters as _register_converters
Using TensorFlow backend.
R#
In R, we can interface with keras as well using one of two packages, either through Rstudio’s “keras” or alternatively “kerasR”. The R code below uses the “keras” package. See website for installation instructions.
library(keras)
library(dplyr)
Reproducibility#
Neural network trainings include randomisation in the starting conditions and evolution.
Including the code below (Python only) will fix the random number generation to a specific value by defining the ‘seeds’ ahead of model fitting, which should lead to a model result that is very close to the results in the article. However, calculations may run slower when fixing seeds.
Python (Optional)#
import tensorflow as tf
import random as rn
import os
os.environ['PYTHONHASHSEED'] = '0'
np.random.seed(42)
rn.seed(12345)
session_conf = tf.ConfigProto(intra_op_parallelism_threads=1, inter_op_parallelism_threads=1)
from keras import backend as K
tf.set_random_seed(1234)
sess = tf.Session(graph=tf.get_default_graph(), config=session_conf)
K.set_session(sess)
Data#
Unfortunately, there are very few public insurance datasets that have a great amount of detail. The example dataset we will use is the “Third party motor insurance claims in Sweden in 1977”, a real-life motor insurance dataset. More information on the dataset can be found here.
This has no perils to split by, however we will create a deep learning model that estimates both claim frequency and average risk premium in a single model. First we will read in and inspect the data:
Python#
df = pd.read_csv("http://www.statsci.org/data/general/motorins.txt", sep='\t') \
.assign(
frequency = lambda x: x.Claims / x.Insured,
severity = lambda x: np.where(x.Claims == 0, 0, x.Payment / x.Claims),
risk_premium = lambda x: x.Payment / x.Insured
)
df.head()
| Kilometres | Zone | Bonus | Make | Insured | Claims | Payment | frequency | severity | risk_premium | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 1 | 1 | 1 | 455.13 | 108 | 392491 | 0.237295 | 3634.175926 | 862.371191 |
| 1 | 1 | 1 | 1 | 2 | 69.17 | 19 | 46221 | 0.274686 | 2432.684211 | 668.223218 |
| 2 | 1 | 1 | 1 | 3 | 72.88 | 13 | 15694 | 0.178375 | 1207.230769 | 215.340285 |
| 3 | 1 | 1 | 1 | 4 | 1292.39 | 124 | 422201 | 0.095946 | 3404.846774 | 326.682348 |
| 4 | 1 | 1 | 1 | 5 | 191.01 | 40 | 119373 | 0.209413 | 2984.325000 | 624.956809 |
R#
df <- read.csv(url("http://www.statsci.org/data/general/motorins.txt"), sep="\t") %>%
mutate(frequency = Claims / Insured,
severity = ifelse(Claims == 0, 0, Payment / Claims),
risk_premium = Payment / Insured)
head(df)
Next, we will split the dataset up into a training dataset and set aside a test dataset for validating our model.
This will also conveniently randomise the ordering of the data. Neural networks train on batches of data records, so we would prefer the data to be in a random order so that each batch is a representative sample rather than the neatly sorted table above.
Python#
train, test = train_test_split(df, test_size=0.2, random_state=12345)
R#
train_ind <- sample(seq_len(nrow(df)), size = floor(0.8 * nrow(df)))
train <- df[train_ind,]
test <- df[-train_ind,]
To rescale the output data, the average frequency, severity and risk premium in the training dataset is calculated.
Python#
totals = train.loc[:, ["Insured", "Claims", "Payment"]].agg('sum')
train_average_frequency = totals["Claims"] / totals["Insured"]
train_average_severity = totals["Payment"] / totals["Claims"]
train_average_risk_premium = totals["Payment"] / totals["Insured"]
print(train_average_frequency, train_average_severity, train_average_risk_premium)
0.04749109486158422 4959.405313081085 235.52758818057862
R#
summary <- train %>% summarise(
train_average_frequency = sum(Claims) / sum(Insured),
train_average_severity = sum(Payment) / sum(Claims),
train_average_risk_premium = sum(Payment) / sum(Insured))
summary
Neural Network#
Designing a neural network architecture is analogous to piecing some building blocks together. We will design the model using the functional API of Keras, which allows us to composite neural network layers to form our model architecture.
Embeddings#
When fitting statistical models, categorical variables typically need to be converted to a series of numerical vectors. Often for GLMs, indicator variables are set.
In deep learning we can use an “embedding” encoding, which will encode the sequence down to a small number of vectors and gets fit as part of the model. We will do this for zone and make.
Python#
zone_input = Input(shape=(1,), name='zone_input')
make_input = Input(shape=(1,), name='make_input')
R#
zone_input = layer_input(shape=c(1), name='zone_input')
make_input = layer_input(shape=c(1), name='make_input')
According to Google’s Tensorflow guide, a rough rule of thumb for setting the size of the output vector of an embedding would be the quartic root (^0.25) of the number of categories. However since the the number of categories is so small, we will just keep to output dimensions of 2.
Python#
zone_embedding = Embedding(output_dim=2, input_dim=7)(zone_input)
zone_embedding = Reshape(target_shape=(2,))(zone_embedding)
make_embedding = Embedding(output_dim=2, input_dim=9)(make_input)
make_embedding = Reshape(target_shape=(2,))(make_embedding)
R#
zone_embedding = layer_embedding(output_dim=2, input_dim=7)(zone_input) %>%
layer_reshape(target_shape=c(2))
make_embedding = layer_embedding(output_dim=2, input_dim=9)(make_input) %>%
layer_reshape(target_shape=c(2))
Other inputs#
Kilometres and Bonus already have an implicit relationship between the value of the factor and the meaning - i.e. higher Kilometres factors represents a higher amount of kilometres driven, so we will put in the data as is.
Python#
kilometres_input = Input(shape=(1,), name='kilometres_input')
bonus_input = Input(shape=(1,), name='bonus_input')
R#
kilometres_input = layer_input(shape=c(1), name='kilometres_input')
bonus_input = layer_input(shape=c(1), name='bonus_input')
We then concatenate the inputs together.
Python#
x = concatenate([zone_embedding, make_embedding, kilometres_input, bonus_input])
R#
x = layer_concatenate(c(zone_embedding, make_embedding, kilometres_input, bonus_input))
Dense layers#
Next we get to the actual “brains” of the deep learning model. For the example we will keep it simple with a sequential series of dense layers, however it is possible to use more complex structures or choices of layers which may improve prediction performance.
Python#
x = Dense(64, activation='relu')(x)
x = Dense(64, activation='relu')(x)
x = Dense(64, activation='relu')(x)
R#
x = x %>% layer_dense(64, activation='relu') %>%
layer_dense(64, activation='relu') %>%
layer_dense(64, activation='relu')
Here we have added three hidden “layers”, with each layer consisting of 64 nodes (or “neurons”).
This should give enough flexibility for non-linear effects and interactions, while not adding too much complexity, given the scale of the dataset.
Each node uses a [rectified linear unit](https://en.wikipedia.org/wiki/Rectifier_(neural_networks), or “ReLU” activation function, which is akin to a truncated linear model, with the truncation giving the overal network its non-linear capabilties.
Ideas to potentially explore with the goal of improving predictivness include adjusting the number of layers, or adding drop out, batch normalisation, or skip layer structures into the model.
The deep learning approach also opens the possibility of using more complex data such as images as inputs into the model. Even a small image dataset can be leveraged to provide insights by connecting it to one of many publically available pre-trained image recognition networks and then “fine-tuned” to provide insights into your motor risk rating.
Output#
Finally, we add the output regression layer that describes our three outcomes of interest:
Python#
frequency_output = Dense(1, activation='relu', name='frequency')(x)
severity_output = Dense(1, activation='relu', name='severity')(x)
risk_premium_output = Dense(1, activation='relu', name='risk_premium')(x)
R#
frequency_output = x %>% layer_dense(1, activation='relu', name='frequency')
severity_output = x %>% layer_dense(1, activation='relu', name='severity')
risk_premium_output = x %>% layer_dense(1, activation='relu', name='risk_premium')
More outputs can be added - if there are multiple risk perils, you could then include each of the frequency, severity and risk premium values as an additional output.
It is also possible to include input variables as outputs to infer missing values or just help the model “understand” the features - in fact the winning solution of a claims prediction Kaggle competition heavily used denoising autoencoders together with model stacking and ensembling - read more here.
Model Definition#
Python#
model = Model(inputs=[zone_input, make_input, kilometres_input, bonus_input],
outputs=[frequency_output, severity_output, risk_premium_output])
R#
model = keras_model(inputs=c(zone_input, make_input, kilometres_input, bonus_input),
outputs=c(frequency_output, severity_output, risk_premium_output))
The standard poisson will be used for frequency. A simple mean squared error will be used for risk premium.
Keras allows definition of custom loss functions, so it would be possible to improve this by potentially including a gamma claim size (as suggested by the paper from which the dataset comes from) and a tweedie risk premium model.
However for this snippet we will just keep it simple and use the available standard losses.
Python#
model.compile(optimizer='adam',
loss={'risk_premium': 'mean_squared_error', 'frequency': 'poisson', 'severity': 'mean_squared_logarithmic_error'},
loss_weights={'risk_premium': 1.0, 'frequency': 1.0, 'severity': 1.0})
R#
model %>% compile(optimizer='adam',
loss=list(risk_premium='mean_squared_error',
frequency='poisson',
severity='mean_squared_logarithmic_error'),
loss_weights=list(risk_premium= 1.0, frequency= 1.0, severity= 1.0))
This is how our model looks like diagrammatically:
Python#
SVG(model_to_dot(model).create(prog='dot', format='svg'))

R (text summary only)#
summary(model)
Flexibility in Inputs and Outputs#
While it is not possible with our example dataset based on historical data, it is worth noting the flexibility that a neural network can give to your model inputs - for example:
images (e.g. photos of the vehicle),
freeform text descriptions (e.g. claims diary of accident history),
time series (e.g. driving behaviours)
These can all be included as predictors if they were available - leveraging image recognition and natural language processing models and other advances in deep learning.
Outputs can also be the images, freeform texts or time series. They can also include the missing data in inputs - for example, the first place solution in the Porto Seguro Kaggle data mining competition was based on auto-encoders which predicts the inputs as outputs.
Fit#
Fitting the model. Some things to note are:
keras factors for embeddings count from 0, 1, 2… but our data is set up as 1, 2 3 so we need to subtract 1 from each predictor,
sample weights are set individually - frequency and risk premium use the same exposure weights, but had we included claim size, that would use claim count as the weight,
do some basic normalising - on the Bonus and Kilometres inputs and particularly on the outputs to get frequency and risk premium to be in the same scale.
Python#
def InputDataTransformer(x):
return {
'kilometres_input': (x.Kilometres.values - 1) / 5,
'zone_input': x.Zone.values - 1,
'bonus_input': (x.Bonus.values - 1) / 7,
'make_input': x.Make.values - 1}
model.fit(
InputDataTransformer(train),
{'frequency': train.frequency.values / train_average_frequency,
'severity': train.severity.values / train_average_severity,
'risk_premium': train.risk_premium.values / train_average_risk_premium},
sample_weight={
'frequency': train.Insured.values,
'severity': train.Claims.values,
'risk_premium': train.Insured.values
},
epochs=40, batch_size=32)
Epoch 1/40
1745/1745 [==============================] - 1s 378us/step - loss: 2576.4842 - frequency_loss: 1495.8723 - severity_loss: 15.2120 - risk_premium_loss: 1065.3999
Epoch 2/40
1745/1745 [==============================] - 0s 75us/step - loss: 1579.1398 - frequency_loss: 1146.6263 - severity_loss: 2.6367 - risk_premium_loss: 429.8768
Epoch 3/40
1745/1745 [==============================] - 0s 69us/step - loss: 1286.9174 - frequency_loss: 1045.1732 - severity_loss: 3.3395 - risk_premium_loss: 238.4046
Epoch 4/40
1745/1745 [==============================] - 0s 80us/step - loss: 1211.8722 - frequency_loss: 1020.3159 - severity_loss: 3.3936 - risk_premium_loss: 188.1627
Epoch 5/40
1745/1745 [==============================] - 0s 69us/step - loss: 1176.7366 - frequency_loss: 1008.0177 - severity_loss: 3.0215 - risk_premium_loss: 165.6974
Epoch 6/40
1745/1745 [==============================] - 0s 57us/step - loss: 1160.6227 - frequency_loss: 1003.7292 - severity_loss: 2.5391 - risk_premium_loss: 154.3544
Epoch 7/40
1745/1745 [==============================] - 0s 69us/step - loss: 1150.7917 - frequency_loss: 1000.5314 - severity_loss: 2.2280 - risk_premium_loss: 148.0323
Epoch 8/40
1745/1745 [==============================] - 0s 46us/step - loss: 1148.0303 - frequency_loss: 999.7820 - severity_loss: 1.7652 - risk_premium_loss: 146.4831
Epoch 9/40
1745/1745 [==============================] - 0s 39us/step - loss: 1145.7089 - frequency_loss: 999.1424 - severity_loss: 1.5042 - risk_premium_loss: 145.0623
Epoch 10/40
1745/1745 [==============================] - 0s 34us/step - loss: 1142.1324 - frequency_loss: 998.8911 - severity_loss: 1.2705 - risk_premium_loss: 141.9709
Epoch 11/40
1745/1745 [==============================] - 0s 46us/step - loss: 1137.5478 - frequency_loss: 997.9134 - severity_loss: 1.1348 - risk_premium_loss: 138.4996
Epoch 12/40
1745/1745 [==============================] - 0s 34us/step - loss: 1137.4215 - frequency_loss: 997.7291 - severity_loss: 1.0760 - risk_premium_loss: 138.6164
Epoch 13/40
1745/1745 [==============================] - 0s 40us/step - loss: 1133.3355 - frequency_loss: 996.5345 - severity_loss: 0.9844 - risk_premium_loss: 135.8166
Epoch 14/40
1745/1745 [==============================] - 0s 40us/step - loss: 1131.6330 - frequency_loss: 996.5850 - severity_loss: 0.9626 - risk_premium_loss: 134.0853
Epoch 15/40
1745/1745 [==============================] - 0s 37us/step - loss: 1132.3984 - frequency_loss: 996.4491 - severity_loss: 0.9251 - risk_premium_loss: 135.0242
Epoch 16/40
1745/1745 [==============================] - 0s 43us/step - loss: 1131.7467 - frequency_loss: 996.9224 - severity_loss: 0.9063 - risk_premium_loss: 133.9181
Epoch 17/40
1745/1745 [==============================] - 0s 46us/step - loss: 1129.9941 - frequency_loss: 995.8470 - severity_loss: 0.8818 - risk_premium_loss: 133.2653
Epoch 18/40
1745/1745 [==============================] - 0s 115us/step - loss: 1136.2895 - frequency_loss: 997.5839 - severity_loss: 0.8912 - risk_premium_loss: 137.8144
Epoch 19/40
1745/1745 [==============================] - 0s 75us/step - loss: 1130.5242 - frequency_loss: 996.5334 - severity_loss: 0.8940 - risk_premium_loss: 133.0969
Epoch 20/40
1745/1745 [==============================] - 0s 50us/step - loss: 1127.7015 - frequency_loss: 995.9074 - severity_loss: 0.8783 - risk_premium_loss: 130.9158
Epoch 21/40
1745/1745 [==============================] - 0s 53us/step - loss: 1125.8479 - frequency_loss: 995.1697 - severity_loss: 0.8580 - risk_premium_loss: 129.8203
Epoch 22/40
1745/1745 [==============================] - 0s 43us/step - loss: 1127.6638 - frequency_loss: 995.6313 - severity_loss: 0.8427 - risk_premium_loss: 131.1897
Epoch 23/40
1745/1745 [==============================] - 0s 40us/step - loss: 1124.9932 - frequency_loss: 994.5914 - severity_loss: 0.8554 - risk_premium_loss: 129.5464
Epoch 24/40
1745/1745 [==============================] - 0s 35us/step - loss: 1127.6583 - frequency_loss: 995.0747 - severity_loss: 0.8425 - risk_premium_loss: 131.7410
Epoch 25/40
1745/1745 [==============================] - 0s 46us/step - loss: 1124.8433 - frequency_loss: 994.2487 - severity_loss: 0.8253 - risk_premium_loss: 129.7693
Epoch 26/40
1745/1745 [==============================] - 0s 74us/step - loss: 1127.7154 - frequency_loss: 996.0589 - severity_loss: 0.8291 - risk_premium_loss: 130.8273
Epoch 27/40
1745/1745 [==============================] - 0s 98us/step - loss: 1127.4021 - frequency_loss: 996.5992 - severity_loss: 0.8513 - risk_premium_loss: 129.9517
Epoch 28/40
1745/1745 [==============================] - 0s 45us/step - loss: 1127.3233 - frequency_loss: 996.1896 - severity_loss: 0.8132 - risk_premium_loss: 130.3205
Epoch 29/40
1745/1745 [==============================] - 0s 40us/step - loss: 1122.5198 - frequency_loss: 994.2507 - severity_loss: 0.8180 - risk_premium_loss: 127.4511
Epoch 30/40
1745/1745 [==============================] - 0s 40us/step - loss: 1121.7726 - frequency_loss: 993.9928 - severity_loss: 0.8055 - risk_premium_loss: 126.9742
Epoch 31/40
1745/1745 [==============================] - 0s 82us/step - loss: 1122.6986 - frequency_loss: 993.6934 - severity_loss: 0.7891 - risk_premium_loss: 128.2160
Epoch 32/40
1745/1745 [==============================] - 0s 89us/step - loss: 1122.3087 - frequency_loss: 994.4129 - severity_loss: 0.7747 - risk_premium_loss: 127.1210
Epoch 33/40
1745/1745 [==============================] - 0s 52us/step - loss: 1126.8087 - frequency_loss: 995.5003 - severity_loss: 0.7701 - risk_premium_loss: 130.5384
Epoch 34/40
1745/1745 [==============================] - 0s 52us/step - loss: 1122.1210 - frequency_loss: 994.2129 - severity_loss: 0.7666 - risk_premium_loss: 127.1415
Epoch 35/40
1745/1745 [==============================] - 0s 45us/step - loss: 1123.9050 - frequency_loss: 995.0833 - severity_loss: 0.7603 - risk_premium_loss: 128.0613
Epoch 36/40
1745/1745 [==============================] - 0s 51us/step - loss: 1119.8890 - frequency_loss: 993.2532 - severity_loss: 0.7509 - risk_premium_loss: 125.8849
Epoch 37/40
1745/1745 [==============================] - 0s 46us/step - loss: 1119.8933 - frequency_loss: 993.8133 - severity_loss: 0.7344 - risk_premium_loss: 125.3456
Epoch 38/40
1745/1745 [==============================] - 0s 51us/step - loss: 1119.7043 - frequency_loss: 993.3680 - severity_loss: 0.7384 - risk_premium_loss: 125.5979
Epoch 39/40
1745/1745 [==============================] - 0s 52us/step - loss: 1119.2908 - frequency_loss: 993.1987 - severity_loss: 0.7300 - risk_premium_loss: 125.3621
Epoch 40/40
1745/1745 [==============================] - 0s 45us/step - loss: 1119.1891 - frequency_loss: 993.4587 - severity_loss: 0.7206 - risk_premium_loss: 125.0097
<keras.callbacks.History at 0x1e20349e6d8>
R#
InputDataTransformer <- function(x){
list(
kilometres_input= (x$Kilometres - 1) / 5,
zone_input= (x$Zone - 1),
bonus_input= (x$Bonus - 1) / 7,
make_input= x$Make - 1
)}
model %>% fit(
x=InputDataTransformer(train),
y=list(
frequency=train$frequency / summary$train_average_frequency,
severity=train$severity / summary$train_average_severity,
risk_premium=train$risk_premium / summary$train_average_risk_premium),
sample_weight=list(
frequency=train$Insured,
severity=train$Claims,
risk_premium=train$Insured),
epochs=40, batch_size=32)
Model Validation#
We will now apply this to the test set to see how well the model has worked.
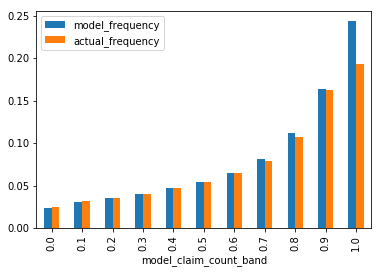
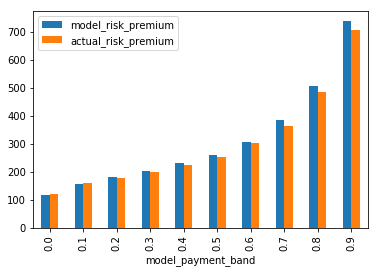
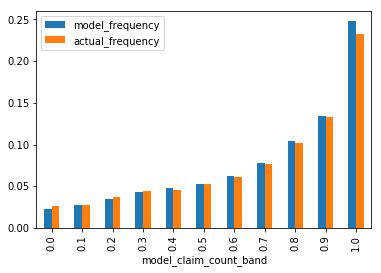
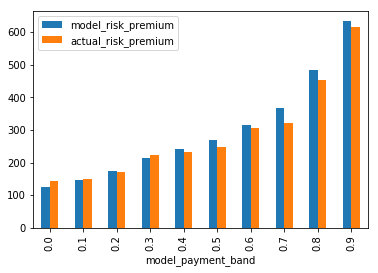
The plots below show the observations ordered from least risky to most risky, with the modelled vs actual frequency and risk premiums, for the training and test sets.
Python#
def predict_and_plot(df, train_average_frequency, train_average_risk_premium):
model_frequency, model_severity, model_risk_premium = model.predict(InputDataTransformer(df))
# Reverse the normalisation
# Score, sort by lowest to higher
df_new = df.assign(model_frequency = model_frequency * train_average_frequency,
model_risk_premium = model_risk_premium * train_average_risk_premium) \
.assign(model_payment = lambda x: x.model_risk_premium * x.Insured,
model_claim_count = lambda x: x.model_frequency * x.Insured) \
.sort_values(by=['model_frequency']) \
.assign(model_claim_count_band = lambda x: np.floor(x.model_claim_count.cumsum() / x.model_claim_count.agg('sum') * 10) / 10) \
.sort_values(by=['model_risk_premium']) \
.assign(model_payment_band = lambda x: np.floor(x.model_payment.cumsum() / x.model_payment.agg('sum') * 10) / 10)
# Summarise and plot frequency by weighted decile rank
df_new.loc[:,['model_claim_count_band', 'Insured', 'Claims', 'model_claim_count']] \
.groupby('model_claim_count_band') \
.agg('sum') \
.assign(model_frequency = lambda x: x.model_claim_count / x.Insured,
actual_frequency = lambda x: x.Claims / x.Insured) \
.loc[:,['model_frequency', 'actual_frequency']] \
.plot.bar()
# Summarise and plot risk premium by weighted decile rank
df_new.loc[:,['model_payment_band', 'Insured', 'Payment', 'model_payment']] \
.groupby('model_payment_band') \
.agg('sum') \
.assign(model_risk_premium = lambda x: x.model_payment / x.Insured,
actual_risk_premium = lambda x: x.Payment / x.Insured) \
.loc[:,['model_risk_premium', 'actual_risk_premium']] \
.plot.bar()
return df_new
train = predict_and_plot(train, train_average_frequency, train_average_risk_premium)
test = predict_and_plot(test, train_average_frequency, train_average_risk_premium)
R#
predict_and_plot <- function(df, train_average_frequency, train_average_risk_premium){
predictions <- model %>% predict(InputDataTransformer(df)) %>% as.data.frame()
colnames(predictions) <- c("model_frequency", "model_severity", "model_risk_premium")
# Reverse the normalisation
df_new <- df %>% cbind(predictions) %>%
mutate(model_frequency = model_frequency * train_average_frequency,
model_risk_premium = model_risk_premium * train_average_risk_premium) %>%
mutate(model_payment = model_risk_premium * Insured,
model_claim_count = model_frequency * Insured)
df_summary <- df_new %>%
summarise(model_claim_count_sum = sum(model_claim_count),
model_payment_sum = sum(model_payment))
# Score, sort by lowest to higher
df_new <- df_new %>%
arrange(model_frequency) %>%
mutate(model_claim_count_band = floor(cumsum(model_claim_count) / df_summary$model_claim_count_sum * 10) / 10) %>%
arrange(model_risk_premium) %>%
mutate(model_payment_band = floor(cumsum(model_payment) / df_summary$model_payment_sum * 10) / 10)
# Summarise and plot frequency by weighted decile rank
df_new %>% group_by(model_claim_count_band) %>%
summarise(model_frequency = sum(model_claim_count) / sum(Insured),
actual_frequency = sum(Claims) / sum(Insured)) %>%
select(-model_claim_count_band) %>% as.matrix() %>% t() %>%
barplot(xlab = "Frequency Decile", ylab="Frequency", beside = TRUE)
# Summarise and plot risk premium by weighted decile rank
df_new %>% group_by(model_payment_band) %>%
summarise(model_risk_premium = sum(model_payment) / sum(Insured),
actual_risk_premium = sum(Payment) / sum(Insured)) %>%
select(-model_payment_band) %>% as.matrix() %>% t() %>%
barplot(xlab = "Risk Premium Decile", ylab="Risk Premium", beside = TRUE)
df_new
}
train = predict_and_plot(train, summary$train_average_frequency, summary$train_average_risk_premium)
test = predict_and_plot(test, summary$train_average_frequency, summary$train_average_risk_premium)
Neural networks can be fragile. Data needs to be transformed in the right way, and the model architecture and optimiser settings can all have impact on the model performance. This makes validation tests such as the test data testing above especially important.
The model appears to be performing well even on the test data set, with the best and worse having a wide differential in predicted outcomes, and actual matching well to those predictions. Try and see the variations if you remove the reproducible constraint at the start and train it multiple times. Does the model fit well every time?
In the event a neural network model behaves oddly, some good resources for diagnosing issues can be found here and here.
Run this code in your browser!#
All the Python and R code from this snippet can be run interactively in your browser.
For Python, use the rocket icon at the top of the page and select Colab (fairly quick, requires Google account) or Live Code (slower).
Alternatively, you can use the links below:
Some loading time is expected with the latter, as the Binder server needs to load and start up a virtual machine with all the packages and code installed.
Afterward#
Often media article tends to describe “AI” in science-fiction or occult terms, but it is important to recognise that it is only a particular class of models. Just like other models, actuaries should ask tough questions about its appropriateness - such as on the quality of data inputs, the understanding of outliers, and the distribution assumptions.
It is also a model with some very useful properties. As we have seen above, a fully functional, multi-tasking neural network for potentially automating general insurance pricing is possible in only around 100 lines of Python or R code. It is not too hard for actuaries with good grounding in statistics to learn, and perhaps it may be useful for your next project!
To learn more on neural networks from first principles, Google’s Intro to Deep Learning seems like a good choice. Alternatively, for those who prefer to plunge straight into applications, there is the fast.ai course - the older v1 of the course uses Keras similar to this tutorial.